In diesem fünften Blogbeitrag geht es um verschiedene Methoden, mit denen die Verteilung von Pods in einem Kubernetes-Cluster optimiert werden kann. Im Einzelnen handelt es sich um folgende Konzepte: Taints and Tolerations, NodeSelector, Node Affinity und Pod Affinity and Anti-Affinity.
Im vorherigen Beiträgen konnten Sie mehr über Kubernetes-Cluster und deren Komponenten erfahren:
- Teil 4 - Workload-Objekte
- Teil 3 - Namespaces, Labels und Annotations
- Teil 2 - API-Server, API Objects
- Teil 1 - Überblick über die Kubernetes Architektur
Was sind Taints und Tolerations?
Taints und Tolerations sind Mechanismen, die sicherstellen, dass Pods nicht auf ungeeigneten Kubernetes-Knoten geplant oder platziert werden. In Bezug auf Kubernetes kann der Begriff Taints mit markiert oder gekennzeichnet übersetzt werden. Taints und Tolerations sind untrennbar miteinander verbunden, da sie als Paar arbeiten. Taints werden zu Knoten hinzugefügt, während Tolerations in der Pod-Spezifikation definiert werden. Wenn ein Taint zu einem Knoten hinzugefügt wird, werden alle Pods abgelehnt, die keine Toleration für diesen Taint haben.
Taints und Tolerations - technische Umsetzung
Die technische Umsetzung ist relativ einfach. Die Worker-Knoten müssen mit entsprechenden Taints versehen werden, z.B. wir wollen erreichen, dass auf den Knoten wn-01 und wn-02 nur die Pods ausgeführt werden, die mit dem Taint „monitoring“ versehen sind.
Diese Befehle fügen den Taint "monitoring" zu den Knoten wn-01 und wn-02 hinzu und verwenden den Effekt "NoSchedule" (wird weiter unter erklärt).
kubectl taint nodes wn-01 monitoring:NoSchedulekubectl taint nodes wn-02 monitoring:NoSchedule
Weiterhin wird eine YAML-Datei erstellt, die diesen Taint macht.
apiVersion: apps/v1kind: Deploymentmetadata: name: mein-deploymentspec: replicas: 3 selector: matchLabels: app: mein-app template: metadata: labels: app: mein-app spec: containers: - name: mein-app image: nginx tolerations: - key: "monitoring" operator: "Exists" effect: "NoSchedule"
Hier ist die visuelle Darstellung der Konfiguration:
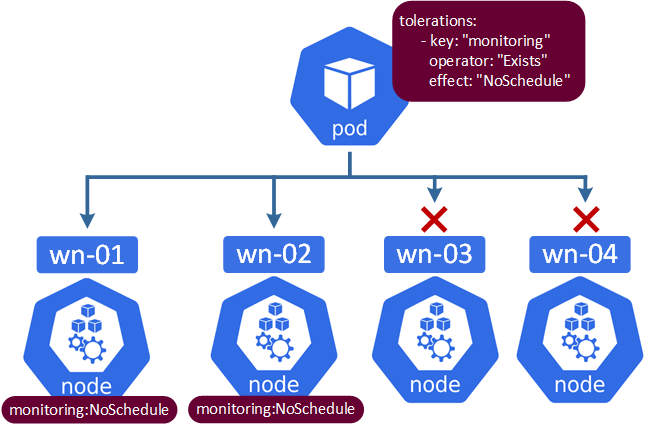
Taint-Optionen (Effekten)
NoSchedule - bedeutet, dass der Kubernetes Scheduler keine neuen Pods auf dem Knoten zulässt, wenn diese den Taint nicht tolerieren. NoSchedule hat keinen Einfluss auf Pods, die bereits auf dem Knoten laufen.
PreferNoSchedule - in diesem Fall versucht der Kubernetes Scheduler die Planung von Pods zu vermeiden, die keine Toleranzen für fehlerhafte Knoten haben. Diese Option wird verwendet, wenn keine besser geeigneten Knoten verfügbar sind.
NoExecute – dies ist die härtere Version „NoSchedule“. NoExecute entfernt (evakuiert) Pods, die bereits auf dem Knoten laufen, wenn sie den Taint nicht tolerieren.
Typische Verwendungsfälle
Die NoSchedule-Option wird häufig verwendet, wenn die Notwendigkeit besteht, Worker-Knoten für bestimmte Aufgaben oder Benutzergruppen zu reservieren oder sicherzustellen, dass nur bestimmte Pods auf Knoten mit spezieller Hardware (wie z.B. wie GPUs) geplant werden.
Ein Beispiel ist die garantierte Nutzung durch eine bestimmte Benutzergruppe oder die Verwendung einer bestimmten Hardware:
kubectl taint nodes <nodename> cityCologne:NoSchedulekubectl taint nodes <nodename> grafikkarte:NoSchedule
Die Taints können etwas komplizierter sein, wenn dies notwendig und sinnvoll ist, z.B:
kubectl taint nodes <node-name> grafikkarte=true:NoSchedule
In diesem Fall wird die Tolerations in spec so aussehen:
spec: containers: - name: podname image: imagename tolerations: - key: "grafikkarte" operator: "Equal" value: "true" effect: "NoSchedule"
Der NoExecute-Effekt wird in den folgenden Situationen verwendet:
Der andere Anwendungsfall wäre, dass ein Knoten aufgrund eines Netzwerkausfalls oder aus anderen Gründen nicht erreichbar ist. In diesem Fall kann dem Knoten kein Taint direkt zugewiesen werden, sondern der Zustand des Knotens als wird in der Kubernetes API mit dem Schlüssel "nicht erreichbar" (node.kubernetes.io/unreachable) oder "nicht bereit" (node.kubernetes.io/not-ready) markiert und dem Effekt NoExecute zugewiesen. Die Unterschiede zwischen unreachable und not-ready werden weiter unten erklärt.
Zusätzlich kann dem Taint eine tolerationSeconds-Option hinzugefügt werden. Die Option tolerationSeconds bestimmt, wie lange der Knoten von der Verteilung ausgeschlossen bleibt. Der Standardwert ist 300 Sekunden, kann aber in der Pod-Spezifikation überschrieben werden.
Hier ist die Liste der Labels, die zur Beschreibung des Knoten-Zustandes eingesetzt werden. Die Labels werden nicht nur in Verbindung mit Taints verwendet.
| Zustand | Beschreibung |
|---|---|
| node.kubernetes.io/not-ready | not-ready wird automatisch hinzugefügt, wenn der Status des Kubelet Heartbeats von Ready zu NotReady wechselt. Der mögliche Anwendungsfall könnte z.B. sein, dass der Control-Node den Worker zwar netzwerktechnisch erreicht, aber den Workload nicht ausführen kann. |
| node.kubernetes.io/unreachable | unreachable wird ebenfall automatisch hinzugefügt, wenn der Kubernetes Control-Nodes keine Verbindung zum Worker-Nodes herstellen kann (Netzwerkprobleme, Worker heruntergefahren, Kubelet läuft nicht) |
| node.kubernetes.io/unschedulable | unschedulable bedeutet, dass keine neuen Pods auf dem Knoten geplant werden können. Dies kann durch den Administrator oder aufgrund von Ressourcenknappheit festgelegt werden (die drei unteren Punkte). |
| node.kubernetes.io/network-unavailable | network-unavailable bedeutet, dass das Netzwerk des Knoten nicht verfügbar ist |
| node.kubernetes.io/memory-pressure | memory-pressure bedeutet, dass der Speicher auf dem Knoten knapp wird und der Workload möglicherweise nicht mehr ausgeführt werden kann. |
| node.kubernetes.io/disk-pressure | disk-pressure weist auf eine hohe Auslastung der Festplatten auf den Knoten hin |
| node.kubernetes.io/pid-pressure | pid-pressure bedeutet, dass die Anzahl der noch verfügbaren Prozess-IDs (PIDs) auf dem Knoten knapp wird und neue Prozesse nicht gestartet werden können. |
Alle oberen Labels werden abhängig vom Knotenstatus mit dem Befehl kubectl describe node angezeigt:
- not-ready und unreachable im Abschnitt Taints.
- network-unavailable, memory-pressure, disk-pressure und pid-pressure im Abschnitt Conditions.
- Unschedulable kommt separat.
Was ist NodeSelector?
NodeSelector ist eine relativ einfache Methode, um einen Pod einem bestimmten Node zuzuweisen. Die Konfiguration des NodeSelectors erfolgt durch Zuweisung von Schlüssel-Wert-Paaren in der Pod-Spezifikation.
In unserem Beispiel wollen wir sicherstellen, dass bestimmte Knoten nur auf den Pods laufen, die mit SSDs ausgestattet sind. Zuerst weisen wir einem Node ein Label zu:
kubectl label nodes <podname> disktype=ssd
So kann die Pod-Konfiguration aussehen:
apiVersion: v1kind: Podmetadata: name: mein-podspec: containers: - name: mein-container image: mein-nginx nodeSelector: disktype: ssd
Was ist Node Affinity?
Node Affinity kann als Erweiterung von NodeSelector angesehen werden. Node Affinity bietet mehr Flexibilität und kann zwischen „erforderlichen" oder „harten“ Regeln und "bevorzugten" oder „weichen“ Regeln unterscheiden.
Die Trennung zwischen den erforderlichen und den bevorzugten Anforderungen erfolgt auf der Grundlage dieser Optionen:
requiredDuringSchedulingIgnoredDuringExecution – harte Anforderung
preferredDuringSchedulingIgnoredDuringExecution - weiche Anforderung
Die folgenden Beispiele veranschaulichen diese Optionen:
Labels hinzufügen:
kubectl label nodes <node-name> disk=ssd-sata6kubectl label nodes <node-name> disk=ssd-nvme
Aufgrund der harten Anforderung können Pods nur auf Knoten mit dem Label „disk“ und dem Wert "ssd-nvme" geplant werden. Wenn kein solcher Knoten vorhanden ist, werden die Pods nirgendwo gestartet.
apiVersion: apps/v1kind: DaemonSetmetadata: name: prometheus-daemonset namespace: defaultspec: selector: matchLabels: name: prometheus template: metadata: labels: name: prometheus spec: affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: disk operator: In values: - ssd-nvme containers: - name: prometheus image: prometheus:2.44.0 ports: - containerPort: 80
kind: DaemonSetmetadata: name: prometheus-daemonset namespace: defaultspec: selector: matchLabels: name: prometheus template: metadata: labels: name: prometheus spec: affinity: nodeAffinity: preferredDuringSchedulingIgnoredDuringExecution: - weight: 1 preference: matchExpressions: - key: disk operator: In values: - ssd-sata6 containers: - name: prometheus image: prometheus:2.44.0 ports: - containerPort: 80
Der Parameter weight wird in preferredDuringSchedulingIgnoredDuringExecution verwendet und kann einen Wert zwischen 1 und 100 haben. Der Wert stellt die Priorität dar, je höher der Wert, desto mehr wird dieses Pod vom Scheduler bevorzugt.
Damit der Parameter weight richtig verwendet werden kann, sollten die Optionen (preferredDuringSchedulingIgnoredDuringExecution) mit mehreren Auswahlmöglichkeiten versehen und entsprechend gewichtet werden. Hier ist eine mögliche Konfiguration:
preferredDuringSchedulingIgnoredDuringExecution: - weight: 1 preference: matchExpressions: - key: disk operator: In values: - ssd-sata6 - weight: 5 preference: matchExpressions: - key: disk operator: In values: - ssd-nvme
Was ist Pod Affinity / Pod Anti-Affinity?
Pod Affinity
Pod Affinity stellt sicher, dass einzelne Pods oder eine Gruppe von Pods auf demselben Knoten (oder einer Gruppe von Knoten) ausgeführt werden. Dies ist für Anwendungen interessant, die in einer gewissen Abhängigkeit zueinander stehen und eine optimale Netzwerkkommunikation benötigen.
Analog zu den Node Affinity verwenden Pod Affinity gleiche Mechanismen:
- requiredDuringSchedulingIgnoredDuringExecution
- preferredDuringSchedulingIgnoredDuringExecution
Beispiel:
Im folgenden Beispiel wird der Scheduler versuchen, die drei Pods des Webservers auf dem gleichen Knoten zu platzieren, auf dem bereits die Datenbank ("app=database") läuft.
apiVersion: apps/v1kind: Deploymentmetadata: name: web-serverspec: replicas: 3 selector: matchLabels: app: web-server template: metadata: labels: app: web-server spec: affinity: podAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: app operator: In values: - database topologyKey: "kubernetes.io/hostname" containers: - name: web-server image: web-server-container
Die Bindung an einen Knoten wird durch das Schlüssel-Wert-Paar bestimmt: topologyKey: "kubernetes.io/hostname". Die Manifestdatei für das Datenbank-Deployment muss dementsprechend das Schlüssel-Wert-Paar "app: database" enthalten. Mögliche Operatoren sind: In, NotIn, Exists, DoesNotExist, Lt, Gt.
Datenbank-Deployment:
apiVersion: apps/v1kind: Deploymentmetadata: name: databasespec: replicas: 1 selector: matchLabels: app: database template: metadata: labels: app: database spec: containers: - name: database image: meine-database
Hier ist ein weiteres Beispiel von der offiziellen Kubernetes-Seite. In diesem Fall erfolgt die Platzierung der Pods anhand eines Topologie-Labels "topology.kubernetes.io/zone" (geografische Zone eines Cloud-Providers). Pods werden entweder in europa-nord oder europa-west platziert.
affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: topology.kubernetes.io/zone operator: In values: - europa-nord - europa-west
Pod Anti-Affinity
Pod Anti-Affinity ist natürlich das Gegenteil von Pod Affinity. Mit Pod Anti-Affinity kann sichergestellt werden, dass bestimmte Pods nicht auf demselben Knoten laufen. Diese Option kann bei der Planung von Hochverfügbarkeit nützlich sein. Mit Pod Anti-Affinity kann verhindert werden, dass Pods, die den gleichen Dienst ausführen, auf dem gleichen Node laufen.
Auch hier gelten dieselben Mechanismen:
- requiredDuringSchedulingIgnoredDuringExecution
- preferredDuringSchedulingIgnoredDuringExecution