In diesem Blogbeitrag erhalten Sie einen detaillierten Überblick über die verschiedenen Komponenten der Kubernetes-Architektur und wie diese zusammenarbeiten. Eine allgemeine Information über Kubernetes ist hier zu finden: Kubernetes Vor- und Nachteile
- Teil 5 - Taints & Tolerations, NodeSelector, Affinity
- Teil 4 - Workload Objekte
- Teil 3 - Namespaces, Labels und Annotations
- Teil 2 - API-Server, API Objects
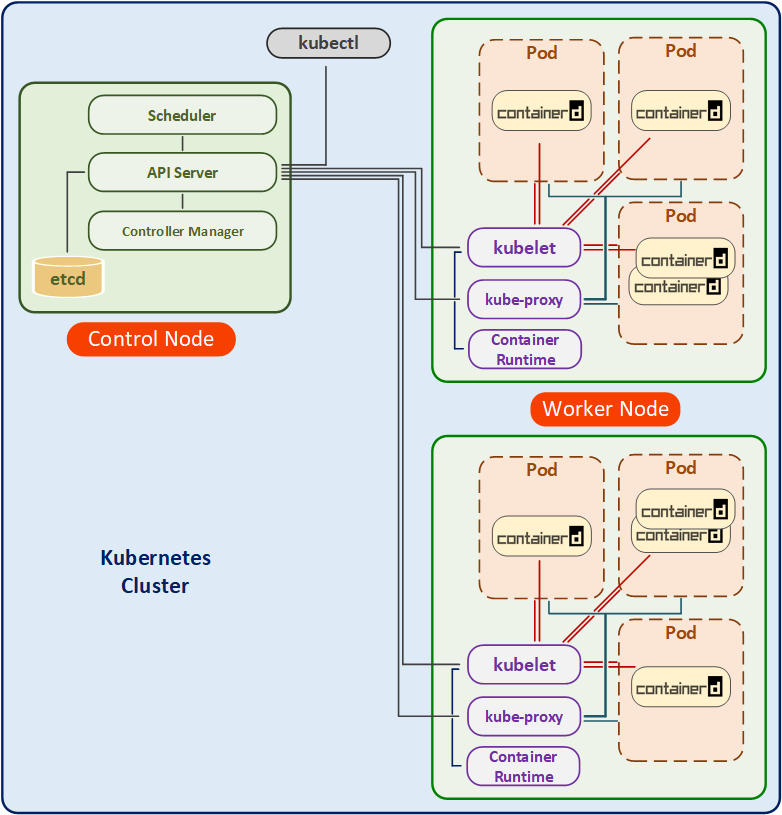
Unter diesem Link finden Sie das obere Architektur-Diagramm, sowie weitere Bilder im Visio-Format: Kubernetes_Architecture_Diagramm_Visio.vsdx
Die Kubernetes-Architektur besteht im Groben aus zwei Schichten. Die erste Schicht könnte man als eine physikalische Schicht bezeichnen. Auf dieser Ebene befinden sich zwei Komponenten: ein oder mehrere Master Nodes sowie ein oder mehrere Worker Nodes.
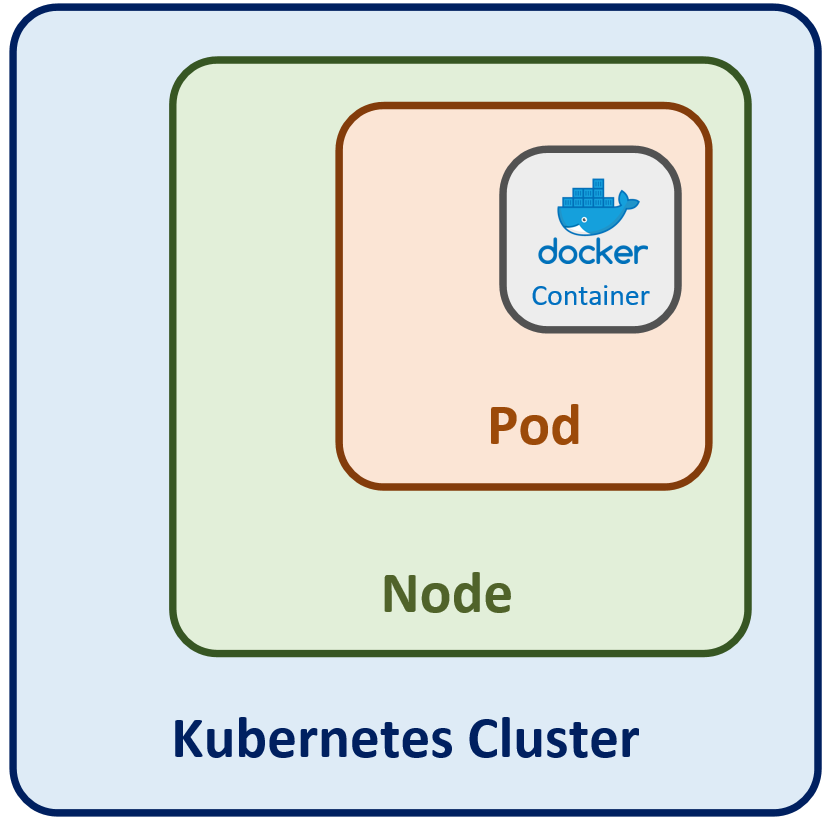
Die weiteren Schichten sind zwei logische Abstraktionen:
- der Kubernetes Cluster selbst, welcher alle Komponenten beinhaltet
- die Pods, in denen einer oder mehrere Container Instanzen ausgeführt werden
Die Abbildung auf der rechten Seite verdeutlich die logische Gliederung der Komponenten: Cluster beinhaltet Nodes, Nodes beinhalten Pods, Pods beinhalten einzelnen Containers.
| Komponente | Kategorie |
| kube-apiserver | Control Plane |
| etcd | Control Plane |
| kube-scheduler | Control Plane |
| kube-controller-manager | Control Plane |
| cloud-controller-manager | Control Plane |
| kubelet | Worker Nodes |
| kube-proxy | Worker Nodes |
| Container Runtime | Worker Nodes |
| Pods | Worker Nodes |
| Configuration Maximums, nicht mehr als... | |
| 110 | Pods pro Node |
| 5000 | Nodes |
| 150 000 | Pods in einem Cluster |
| 300 000 | Containers in einem Cluster |
Control (Master) Node
Der Control Node ist eine wichtige Komponente von Kubernetes und besteht aus mehreren Bestandteilen, die eng miteinander interagieren, um den Kubernetes-Cluster zu steuern und zu verwalten. Hier sind die wichtigsten Komponenten des Control Nodes:
- kube-apiserver
- etcd
- kube-controller-manager
- kube-scheduler
Kubernetes API-Server
Der API-Server ist eine Komponente von Kubernetes, die es ermöglicht, den Cluster zentral zu verwalten und zu steuern. Durch die Verwendung der API können Entwickler und Administratoren Kubernetes-Anwendungen erstellen, die auf die Ressourcen des Clusters zugreifen und diese verwalten können.
Der Kubernetes-API-Server ist das primäre Gateway für die Interaktion mit dem Kubernetes-Cluster. Er bietet eine RESTful-API-Schnittstelle für die Verwaltung der Kubernetes-Ressourcen und ist für die Authentifizierung und Autorisierung von Benutzeranfragen verantwortlich.
Hier sind einige wichtige Funktionen und Merkmale des Kubernetes-API-Servers:
- RESTful API: Der API-Server bietet eine RESTful-API-Schnittstelle, die es ermöglicht, Kubernetes-Ressourcen zu erstellen, abzurufen, zu aktualisieren und zu löschen. Die API ist gut dokumentiert und einfach zu verwenden, was die Entwicklung von Kubernetes-Anwendungen und -Integrationen erleichtert.
- Authentifizierung und Autorisierung: Der API-Server ist für die Authentifizierung und Autorisierung von Benutzeranfragen verantwortlich. Er verwendet verschiedene Authentifizierungs- und Autorisierungsmethoden, um sicherzustellen, dass nur autorisierte Benutzeranfragen ausgeführt werden.
- Skalierbarkeit: Der API-Server ist so konzipiert, dass er skalierbar und belastbar ist. Er kann horizontal skaliert werden, um eine hohe Verfügbarkeit zu gewährleisten, indem mehrere Instanzen des API-Servers gestartet werden.
- Erweiterbarkeit: Der API-Server ist erweiterbar und bietet eine Vielzahl von Erweiterungspunkten. Diese Erweiterungspunkte ermöglichen es, benutzerdefinierte Ressourcen und API-Erweiterungen hinzuzufügen, um spezifische Anforderungen und Anwendungsfälle zu erfüllen.
- Versionskontrolle: Der API-Server unterstützt die Versionskontrolle, die es ermöglicht, verschiedene Versionen von Kubernetes-Ressourcen zu verwalten. Dies ist besonders nützlich, wenn Änderungen an einer Ressource vorgenommen werden müssen, ohne die Stabilität des Clusters zu beeinträchtigen.
etcd
Kubernetes etcd wird für die Speicherung von Konfigurationsdaten und Zustandsinformationen des Clusters verwendet. etcd ist eine zuverlässige, verteilte Datenbank, die von CoreOS entwickelt wurde und auf der einfachen Schlüssel-Wert-Paaren basiert. In Kubernetes wird etcd verwendet, um Informationen über Kubernetes-Ressourcen wie Deployments, Services, Pods und Nodes zu speichern und zu verwalten.
Hier sind einige Funktionen und Merkmale von etcd:
- Hochverfügbarkeit: etcd kann auf mehreren Nodes im Cluster ausgeführt werden, um hohe Verfügbarkeit und Skalierbarkeit zu gewährleisten.
- Konsistenz: etcd ist für die Aufrechterhaltung der Konsistenz der Cluster-Konfigurationsdaten und Zustandsinformationen verantwortlich. Es verwendet einen verteilten Konsensalgorithmus, um sicherzustellen, dass alle Nodes im Cluster auf dem gleichen Stand sind.
- Schnittstelle: etcd bietet eine einfache RESTful-API-Schnittstelle, die es ermöglicht, auf die Konfigurationsdaten und Zustandsinformationen im Cluster zuzugreifen und diese zu verwalten.
- Interaktion mit anderen Komponenten: etcd interagiert eng mit anderen Komponenten in der Architektur von Kubernetes. Der API-Server greift auf etcd zu, um Informationen über Kubernetes-Ressourcen zu speichern und abzurufen. Der Kubernetes-Controller-Manager verwendet etcd, um Informationen über den Cluster-Status zu überwachen und automatisch den Zustand des Clusters anzupassen.
- Sicherheit: etcd bietet verschiedene Sicherheitsfunktionen wie SSL-Verschlüsselung und Zugriffskontrollen, um die Daten im Cluster vor unbefugtem Zugriff zu schützen.
kube-controller-manager
Der Kubernetes kube-controller-manager ist eine von Kubernetes, die für die Überwachung und Verwaltung von Controller-Objekten im Cluster und die Durchsetzung des gewünschten Zustands (Desired State) verantwortlich ist. Diese Objekte automatisieren Aufgaben wie das Skalieren von Anwendungen, die Überwachung von Ressourcen und die Wiederherstellung von ausgefallenen Pods.
Hier sind die Funktionen und Merkmale des kube-controller-managers im Überblick:
- Controller-Algorithmen: Der kube-controller-manager verwendet verschiedene Controller-Algorithmen, um Controller-Objekte zu verwalten. Diese Algorithmen umfassen den Replication-Controller, den Deployment-Controller, den StatefulSet-Controller und den DaemonSet-Controller.
- Interaktion mit anderen Komponenten: Der kube-controller-manager interagiert eng mit anderen Komponenten in der Architektur von Kubernetes. Er greift auf den API-Server zu, um Informationen über den Clusterstatus und Ressourcen abzurufen und Änderungen an den Ressourcen vorzunehmen. Der kube-controller-manager kommuniziert auch mit dem kube-scheduler, um sicherzustellen, dass die Ressourcen des Clusters effektiv genutzt werden.
- Skalierbarkeit: Der kube-controller-manager ist horizontal skalierbar, um eine hohe Verfügbarkeit zu gewährleisten, indem mehrere Instanzen des kube-controller-managers gestartet werden.
- Erweiterbarkeit: Der kube-controller-manager ist erweiterbar und bietet eine Vielzahl von Erweiterungspunkten. Diese Erweiterungspunkte ermöglichen es, benutzerdefinierte Controller-Algorithmen und -Aufgaben hinzuzufügen, um spezifische Anforderungen und Anwendungsfälle zu erfüllen.
kube-scheduler
Der Kubernetes kube-scheduler ist eine Architektur-Komponente, die für die Zuweisung von Pods zu Nodes im Cluster verantwortlich ist. Der Scheduler wählt die geeignete Node aus, auf der ein Pod ausgeführt werden soll, basierend auf verschiedenen Faktoren wie den Ressourcenanforderungen des Pods, der Verfügbarkeit von Nodes und den spezifischen Anforderungen von Anwendungen.
Hier sind einige Funktionen und Merkmale von kube-scheduler:
- Algorithmus: Der kube-scheduler verwendet einen Algorithmus, um die am besten geeignete Node für die Ausführung des Pods zu finden. Der Algorithmus ist anpassbar und kann durch das Hinzufügen von benutzerdefinierten Filtern und Prioritäten erweitert werden.
- Interaktion mit anderen Komponenten: Der kube-scheduler interagiert eng mit anderen Komponenten in der Architektur von Kubernetes. Es greift auf den API-Server zu, um Informationen über den Clusterstatus und die verfügbaren Nodes abzurufen. Es kommuniziert auch mit dem Kubelet auf dem Node, auf dem der Pod läuft, um den Status des Pods zu überwachen.
- Erweiterbarkeit: Der kube-scheduler ist auch erweiterbar. Diese Erweiterungspunkte ermöglichen das Hinzufügen von benutzerdefinierten Filtern und Prioritäten, um spezifische Anforderungen und Anwendungsfälle zu erfüllen.
- Skalierbarkeit: Der kube-scheduler ist analog zum kube-controller-manager horizontal skalierbar.
Worker Nodes
Worker Nodes dienen zur Ausführung von Pods. Ein Worker Node ist ein physischer oder virtueller Computer, auf dem eine Container-Laufzeitumgebung (z.B. containerd) ausgeführt wird. Ein Kubernetes-Cluster kann aus Hunderten oder Tausenden von Worker Nodes bestehen, je nach Größe des Clusters.
Ein Worker Node beinhaltet drei folgende Komponenten:
- kubelet
- kube-proxy
- Container Runtime
Hier sind einige Kernfunktionen und Merkmale von Worker Nodes:
- Ausführung von Pods: Worker Nodes sind dafür verantwortlich, Pods in einer isolierten Umgebung auszuführen.
- Kubelet: Das Kubelet ist ein Agent, der auf jedem Worker Node läuft. Es stellt sicher, dass alle Pods auf dem Node ordnungsgemäß funktionieren und ihren gewünschten Zustand beibehalten.
- Container Runtime: Die Container-Runtime-Umgebung ist verantwortlich für das Starten, Stoppen und Verwalten von Containern innerhalb von Pods. Bis vor kurzem war Docker die am häufigsten verwendete Container-Runtime-Umgebung in Kubernetes, die mittlerweile von containerd abgelöst wurde. Es gibt auch andere Container-Runtime-Umgebungen wie z.B. CRI-O.
kubelet
Kubelet ist eine Komponente in der Architektur des Worker Nodes, die für die Verwaltung von Pods auf einem Worker Node im Cluster verantwortlich ist. Der Kubelet ist ein Agent, der auf jedem Node (kann auch auf den Control Nodes ausgeführt werden) in einem Kubernetes-Cluster läuft. Er ist verantwortlich für das Starten, Überwachen und Stoppen von Pods, basierend auf den Pod-Spezifikationen, die er vom Kubernetes API Server erhält.
Einige Funktionen von Kubelet im Überblick:
- Pod-Verwaltung: Der Kubelet startet, stoppt und überwacht Pods, um sicherzustellen, dass sie effektiv ausgeführt werden.
- Ressourcenverwaltung: Der Kubelet überwacht auch die Ressourcennutzung auf dem Node und stellt sicher, dass genügend Ressourcen für die laufenden Pods zur Verfügung stehen.
- Netzwerk: Der Kubelet ist auch für die Netzwerkverbindung des Pods auf dem Worker Node verantwortlich. Er stellt sicher, dass die IP-Adresse des Pods auf dem Node zugewiesen wird und dass die Netzwerkverbindung des Pods effektiv funktioniert.
- Image-Verwaltung: Der Kubelet ist auch für die Verwaltung von Container-Images auf dem Worker Node verantwortlich. Er lädt benötigte Images herunter und stellt sicher, dass sie auf dem Node verfügbar sind.
- Interaktion mit anderen Komponenten: Der Kubelet kommuniziert mit dem Kubernetes-API-Server, um Informationen über die Ressourcenanforderungen von Pods und die verfügbaren Ressourcen auf dem Node abzurufen.
kube-proxy
Kube-proxy ist für das Routing des Netzwerkverkehrs innerhalb des Clusters zuständig. Kube-proxy ermöglicht es, dass die Anwendungen und Dienste innerhalb des Clusters über ihre Netzwerkadressen erreichbar sind, unabhängig davon, auf welchem Node sie ausgeführt werden.
Kube-proxy verwendet verschiedene Modi, um den Netzwerkverkehr innerhalb des Clusters zu steuern. Hier sind einige wichtige Funktionen und Merkmale von kube-proxy:
- IP-Tables-Modus: In diesem Modus verwendet kube-proxy das IP-Tables-Tool, um den Netzwerkverkehr innerhalb des Clusters zu steuern. IP-Tables ist ein Tool, das es ermöglicht, Netzwerkregeln zu definieren, die den Datenverkehr umleiten oder blockieren können.
- IPVS-Modus: In diesem Modus verwendet kube-proxy das IP Virtual Server-Modul, um den Netzwerkverkehr innerhalb des Clusters zu steuern. IPVS ist ein Load-Balancing-Tool, das es ermöglicht, Netzwerkverkehr auf verschiedene Weise umzuleiten, je nach Bedarf.
- Endpunkt-Modus: In diesem Modus verwendet kube-proxy den Kubernetes-Endpunkt, um den Netzwerkverkehr innerhalb des Clusters zu steuern. Der Endpunkt ist eine abstrakte Repräsentation eines Dienstes innerhalb des Clusters und ermöglicht es, den Netzwerkverkehr zwischen verschiedenen Pods und Diensten umzuleiten.
- Interaktion mit anderen Komponenten: Kube-proxy kommuniziert mit dem Kubernetes API-Server, um Informationen über Dienste und Pods abzurufen und verwendet diese Informationen, um den Netzwerkverkehr innerhalb des Clusters zu steuern.
Container Runtinme
Container-Runtime ist eine Softwarekomponente, die für die Verwaltung bzw. Ausführung von Containern auf einem Worker Node verantwortlich ist.
- Container-Verwaltung: Container-Runtime startet, stoppt und überwacht Container, um sicherzustellen, dass sie effektiv ausgeführt werden.
- Image-Verwaltung: Die Container-Runtime ist für das Herunterladen und Speichern von Container-Images verantwortlich. Diese Images bilden die Grundlage für das Starten von Containern.
Pod
Ein Kubernetes Pod ist die kleinste und einfachste Einheit in der Kubernetes-Architektur und besteht aus einem oder mehreren Containern, die in einem gemeinsamen Netzwerk- und Speicher-Bereich ausgeführt werden. In diesem Bereich können Container auf Dateien zugreifen und miteinander interagieren.
Ein Pod
- ist eine abstrakte Repräsentation eines laufenden Prozesses innerhalb eines Clusters und enthält eine oder mehrere Anwendungen und deren Abhängigkeiten, die gemeinsam ausgeführt werden.
- hat einen Lebenszyklus, der von der Erstellung bis zur Beendigung reicht. Wenn ein Pod beendet wird, werden auch die darin enthaltenen Container beendet.
- ist so konzipiert, dass er auf einem beliebigen Worker Node innerhalb eines Kubernetes-Clusters ausgeführt werden kann, was Flexibilität und Skalierbarkeit ermöglicht.
- hat eine eigene IP-Adresse und kann über das Netzwerk mit anderen Pods und Diensten kommunizieren.
- ist skalierbar, so dass die Anzahl der laufenden Anwendungsinstanzen in einem Cluster dynamisch erhöht oder verringert werden kann.
Container
Ein Kubernetes-Container ist eine isolierte, ausführbare Umgebung, die eine Anwendung mit all ihren Abhängigkeiten enthält. Ein Container kann schnell erstellt und bereitgestellt werden, ohne dass das Host-Betriebssystem oder andere Anwendungen auf demselben Host beeinträchtigt werden.
In Kubernetes gibt es verschiedene Arten von Containern, die je nach Anwendungsfall und Erfordernissen eingesetzt werden können:
-
Standard-Container: Dies ist die grundlegende Form von Containern, die in Kubernetes verwendet wird. Standard-Container können verschiedene Arten von Anwendungen ausführen, einschließlich Webanwendungen, Datenbanken und Hintergrunddienste.
-
Init-Container: Init-Container sind Container, die als Teil des Pod-Startvorgangs ausgeführt werden, bevor der Haupt-Container gestartet wird. Init-Container können verwendet werden, um bestimmte Aufgaben auszuführen, wie z.B. das Einrichten von Konfigurationen, das Herunterladen von Dateien oder das Einrichten von Datenbanken.
-
Sidecar-Container: Sidecar-Container sind zusätzliche Container, die im selben Pod wie der Haupt-Container ausgeführt werden. Sidecar-Container können verwendet werden, um zusätzliche Funktionalitäten wie Protokollierung, Überwachung oder Datensicherheit bereitzustellen.
-
Multi-Container-Pod: Ein Multi-Container-Pod ist ein Pod, der mehrere Container enthält, die zusammenarbeiten, um eine Anwendung auszuführen. Multi-Container-Pods können verwendet werden, um komplexe Anwendungen auszuführen, die aus mehreren Komponenten bestehen.
Hochverfügbarkeit
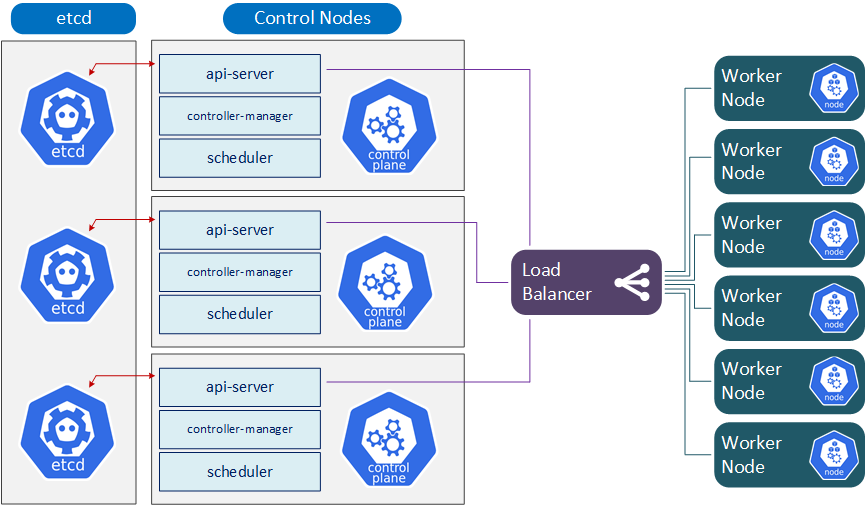
Die Hochverfügbarkeit ist ein wichtiger Aspekt, um sicherzustellen, dass die Anwendungen stets verfügbar und reaktionsschnell sind. Die Erreichung von Hochverfügbarkeit in Kubernetes-Clustern erfordert selbstverständlich eine sorgfältige Planung und Implementierung von Maßnahmen zur Verbesserung der Verfügbarkeit und Ausfallsicherheit von Komponenten und Anwendungen im Cluster.
Hier sind einige bewährte Methoden, um die Hochverfügbarkeit von Kubernetes-Clustern zu erreichen:
- Mehrere Master-Nodes: Durch die Verwendung mehrerer Master-Nodes kann die Verfügbarkeit von Kubernetes-Clustern erhöht werden. Wenn einer der Master-Nodes ausfällt, kann ein anderer Master-Node seine Aufgaben übernehmen.
- Replikation von Kubernetes-Komponenten: Die Replikation von Kubernetes-Komponenten wie dem API-Server, etcd und kube-controller-manager kann dazu beitragen, dass der Cluster immer verfügbar ist, da bei Ausfall einer Komponente eine andere Komponente ihre Aufgaben übernimmt.
- Horizontaler Scaling von Nodes: Durch das horizontale Skalieren von Nodes kann die Verfügbarkeit von Kubernetes-Clustern erhöht werden. Wenn ein Node ausfällt, können die Pods, die auf dem ausgefallenen Node ausgeführt wurden, auf anderen Nodes im Cluster neu gestartet werden.
- Verwendung von Load Balancern: Die Verwendung von Load Balancern kann dazu beitragen, die Verfügbarkeit von Kubernetes-Clustern zu erhöhen. Load Balancer können eingehende Anfragen an verschiedene Nodes im Cluster verteilen, um sicherzustellen, dass Anwendungen stets verfügbar sind.
- Überwachung und Ausfallsicherheit: Eine regelmäßige Überwachung von Kubernetes-Clustern und die Implementierung von Ausfallsicherheitsmaßnahmen können dazu beitragen, dass der Cluster stets verfügbar ist. Dies umfasst die Überwachung von Ressourcen, Pods und Nodes, um sicherzustellen, dass sie ordnungsgemäß funktionieren, sowie die Implementierung von Notfallwiederherstellungsmaßnahmen, um schnell auf Ausfälle im Cluster reagieren zu können.