In diesem Blogbeitrag geht es um die abstrakten Komponenten der Kubernetes-Architektur, insbesondere um die verschiedenen Workload-Objekte. Im vorherigen Beiträgen konnten Sie mehr über Kubernetes-Cluster und deren Komponenten erfahren:
- Teil 5 - Taints & Tolerations, NodeSelector, Affinity
- Teil 3 - Namespaces, Labels und Annotations
- Teil 2 - API-Server, API Objects
- Teil 1 - Überblick über die Kubernetes Architektur
Workload- und Ressourcenobjekte sind wichtige Bestandteile der Kubernetes-Architektur. Diese Objekte beschreiben, wie ein Container oder eine Gruppe von Containern in Kubernetes bereitgestellt und ausgeführt wird. Oft werden die Begriffe „Kubernetes Workload Objekte“ und „Kubernetes Controller“ als absolute Synonyme verwendet, obwohl dies nicht ganz korrekt ist.
Workload-Objekte sind API-Objekte für die Bereitstellung und Verwaltung von Anwendungen und Services in Kubernetes. Ein Workload-Objekt definiert einen bestimmten gewünschten Zustand und Kubernetes sorgt dafür, dass dieser Zustand aufrechterhalten wird.
Die Controller überwachen den aktuellen Zustand des Clusters und nehmen gegebenenfalls Änderungen vor, um den Cluster in den gewünschten Zustand (Desired State) zu bringen.
Zu den gebräuchlichsten Workload-Objekten und Controllern gehören:
- ReplicaSet
- Deployment
- DaemonSet
- StatefulSet
- Job
- CronJob
ReplicaSet
Ein ReplicaSet (auch ReplicaSet Controller genannt) sorgt dafür, dass eine bestimmte Anzahl von Pods (Repliken eines Pods) in einem Cluster ausgeführt werden.
Die Begriffe ReplicaSet und ReplicaSet Controller werden oft "synonym" verwendet. Technisch gesehen handelt es sich um unterschiedliche Konzepte:
- Ein ReplicaSet ist ein Kubernetes-Objekt (YAML-Manifest). Es definiert, wie viele Kopien eines bestimmten Pods ausgeführt werden sollen.
- Der ReplicaSet Controller ist der Teil der Kubernetes-Steuerungsebene und dafür zuständig, dass die gewünschte Anzahl von Pods eines ReplicaSet aufrechtzuerhalten.
Die Aufgabe des ReplicaSet Controllers ist es zu erkennen, dass z.B. ein Pod beendet wurde (aus welchem Grund auch immer) und der Cluster vom gewünschten Zustand abweicht. In diesem Fall sollte der ReplicaSet-Controller den fehlgeschlagenen Pod löschen und eine Create-Anforderung an den API-Server senden, um einen neuen Pod im Cluster zu erstellen und so den gewünschten Zustand wiederherzustellen.
In den seltensten Fällen werden ReplicaSets direkt erstellt. In der Regel werden sie durch Deployments erzeugt.
Die erforderlichen Elemente eines ReplicaSets sind: Pod Template, Replicas, Selector.
Hier ist Beispiel für eine ReplicaSet-Konfiguration:
apiVersion: apps/v1kind: ReplicaSetmetadata: name: mein-replicasetspec: replicas: 3 selector: matchLabels: app: mein-app matchExpressions: - {key: tier, operator: In, values: [frontend]} template: metadata: labels: app: mein-app tier: frontend spec: containers: - name: mein-super-container image: mein-imageErklärung:
- template - hier werden die Eigenschaften der Pods definiert.
- replicas - Anzahl der gleichzeitig laufenden Pods.
- selector - enthält die matchLabels und/oder matchExpressions
- matchLabels - ist ein Schlüssel-Wert-Selektor (wurde im vorherigen Beitrag ausführlich beschrieben). Alle von diesem ReplicaSet verwalteten Pods haben das Label app und den Wert mein-app.
- matchExpressions - können zusätzlich oder anstelle von matchLabels verwendet werden und ermöglichen eine komplexere Logik bei der Auswahl von Pods.
Die matchExpressions-Komponente besteht immer aus drei Teilen: key, operator und values.
- key: Name des Labels, für das die Bedingung gilt.
- operator: Der Operator, der die Bedingung definiert. Die gültigen Operatoren sind: In, NotIn, Exists und DoesNotExist
- values: Ist eine Liste von Werten, die mit dem Label (key) verglichen werden. Dies ist nur für die Operatoren In und NotIn relevant
- In - Dieser Operator überprüft, ob der gegebene Key in der Liste der angegebenen Werte enthalten ist.
- NotIn - Dieser Operator ist das Gegenteil von In und überprüft, ob der gegebene Key nicht in der Liste der Werte enthalten ist.
- Exists - überprüft, ob ein bestimmtes Label unabhängig von seinem Wert vorhanden ist.
- DoesNotExist - Dies ist das Gegenteil von Exists
Deployment
Wie bereits erwähnt, basiert Deployment auf ReplicaSets. Deployments ermöglichen die Aktualisierung oder Änderung von Anwendungen durch die Verwaltung der zugrunde liegenden ReplicaSets. Dies geschieht durch die Erstellung neuer ReplicaSets und die Anpassung ihrer Größe bei gleichzeitiger Reduzierung der Größe bestehender ReplicaSets. Dieser Prozess ermöglicht so genannte "Rolling Updates". "Rolling Updates" ist das schrittweise Hinzufügen neuer Objekte und das Entfernen alter Objekte, ohne dass es zu Ausfallzeiten kommt. Eine weitere wichtige Eigenschaft von Deployment ist die Möglichkeit, die vorgenommenen Änderungen durch Rollback wieder rückgängig zu machen.
Die Aktualisierung oder bessergesagt "Rolling Update" von containerbasieren Applikation funktioniert wie folgt:
- Im ersten Schritt wird ein neues ReplicaSet für die neue Version der Applikation (neues Container-Image) bereitgestellt. Dieses neue ReplicaSet enthält zunächst keine Pods.
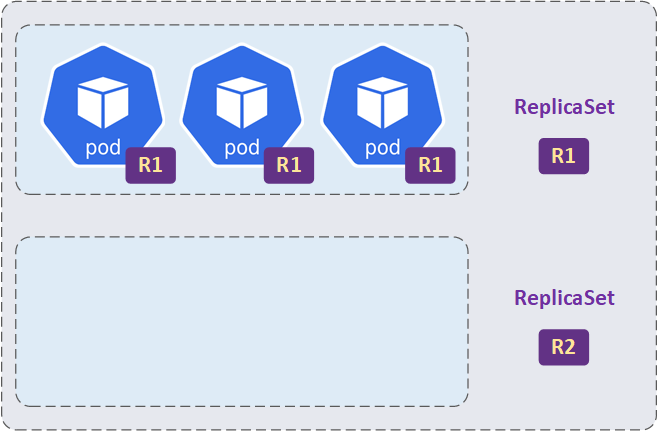
- Danach startet das Deployment neue Pods im neuen ReplicaSet und stoppt gleichzeitig die alten Pods im alten ReplicaSet. Dies geschieht schrittweise, um sicherzustellen, dass die Anwendung weiterhin verfügbar ist und die Lastverteilung sichergestellt ist.
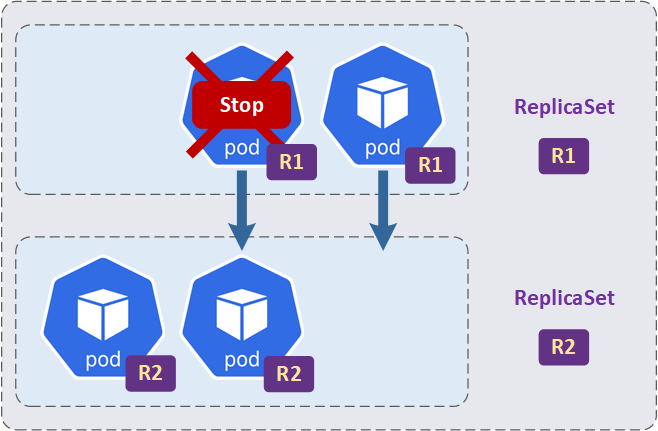
- Dieser Prozess wird fortgesetzt, bis alle alten Pods gestoppt und durch neue Pods ersetzt wurden. Am Ende dieses Prozesses wird das alte ReplicaSet nicht gelöscht und bleibt mit 0 Pods bestehen. Dies ist notwendig, falls während der Aktualisierung Probleme auftreten und der Rollback-Prozess durchgeführt werden soll.
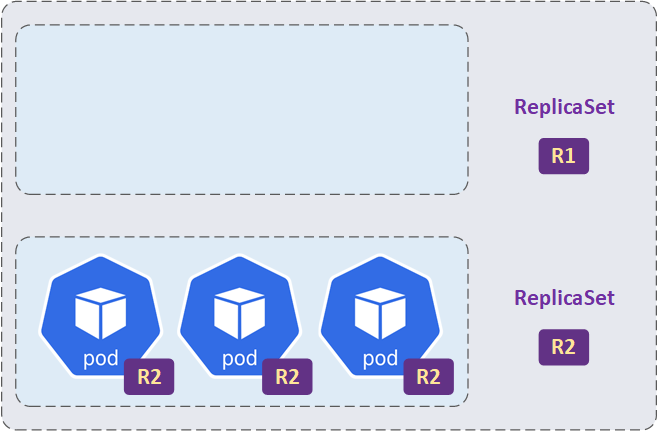
Deployment verwendet auch die gleichen Labels, Selector und Operators wie ReplicaSets.
| ReplicaSet vs. Deployment | ||||
| ReplikaSet | Deployment | |||
| ReplicaSets sind dafür verantwortlich, eine bestimmte Anzahl von Pods einer bestimmten Spezifikation bereitzustellen und aufrechtzuerhalten. | Deployments ermöglicht die Bereitstellung neuer Versionen der Anwendungen durch die schrittweise Erstellung der Pods in den neuen ReplicaSets und die schrittweise Löschung der alten. | |||
RollingUpdate - Parameter
Das RollingUpdate kann durch die beiden Parameter maxUnavailable und maxSurge gesteuert werden. Der Parameter maxUnavailable gibt an, wie viele alte Pods gleichzeitig entfernt werden können. Der Parameter maxSurge angibt, wie viele neue Pods gleichzeitig erstellt werden können. Beide Parameter sind optional und haben den Standardwert 1.
kubectl Befehle für Deployment
Hier sind die gängige kubectl Befehle, die dabei helfen, die Deployments im Cluster zu verwalten und zu überwachen.
- kubectl get deployments: Zeigt eine Liste aller Deployments im Cluster an.
- kubectl describe deployment <deployment-name>: Gibt eine detaillierte Beschreibung des angegebenen Deployments zurück.
- kubectl apply -f <deployment-file>: Erstellt oder aktualisiert ein Deployment auf Basis einer YAML- oder JSON-Datei.
- kubectl scale deployment <deployment-name> --replicas=<number>: Skaliert die Anzahl der Replikate im Deployment auf die angegebene Anzahl.
- kubectl rollout status deployment <deployment-name>: Überprüft den Rollout-Status des Deployments.
- kubectl rollout undo deployment <deployment-name>: Setzt den Rollout auf eine vorherige Version des Deployments zurück.
- kubectl rollout history deployment <deployment-name>: Zeigt eine Liste der Rollout-Historie des Deployments an.
- kubectl delete deployment <deployment-name>: Löscht das angegebene Deployment aus dem Cluster.
DaemonSet
Das DaemonSet sorgt dafür, dass eine Kopie eines bestimmten Pods auf allen oder einigen Knoten eines Clusters läuft. Wenn ein neuer Knoten zum Cluster hinzugefügt wird, startet das DaemonSet einen Pod auch auf diesem Knoten. Mit „einige Knoten“ ist gemeint, dass DaemonSets so konfiguriert werden können, dass sie nur auf bestimmten Knoten laufen.
Die DaemonSets in Kubernetes werden häufig für hauptsächlich technische Zwecke auf den Nodes verwendet. Dazu gehören: Logging-Dienste, Überwachungssysteme, Netzwerkdienste oder Sicherheitsdienste.
Im Gegensatz zu den anderen Kubernetes Controllern (ReplicaSets und Deployments) verwendet das DaemonSet nicht nur Labels und Selectors (hier detailliert beschrieben), sondern auch das nodeSelector oder nodeAffinity Attribut, um Pods einem bestimmten Node zuzuweisen.
Beispiel eines YAML-Manifestes für DaemonSet:
apiVersion: apps/v1kind: DaemonSetmetadata: name: prometheus-daemonset namespace: defaultspec: selector: matchLabels: name: prometheus template: metadata: labels: name: prometheus spec: nodeSelector: disk: ssd containers: - name: prometheus image: prometheus:2.44.0 ports: - containerPort: 80Beschreibung einigen Spezifikationen:
- spec: in dieser Sektion werden die DaemonSets-Spezifikationen definiert.
- selector: - über den Selector findet das DaemonSet die zu verwaltenden Pods. In diesem Fall "name: prometheus"
- nodeSelector: Dieser Parameter bestimmt, auf welchen Knoten die Pods laufen sollen. In diesem Fall auf den Knoten, die mit den SSDs bestückt sind ("disk: ssd").
StatefulSet
Ein Kubernetes StatefulSet ist eine weitere Kubernetes-Ressource, die für die Bereitstellung und Skalierung einer Gruppe von Pods verantwortlich ist. Wie der Name StatefulSet schon andeutet, handelt es sich um zustandsbehaftete Anwendungen. Die von StatefulSet erzeugten Pod Instanzen haben eine eindeutige und beständige Identität.
Diese Identität muss auch dann erhalten bleiben, wenn die Pods neu geplant, aktualisiert, gelöscht oder neu erstellt werden. Typische Anwendungsbeispiele für stateful Pods sind Datenbanken.
Hier sind einige der Hauptmerkmale von StatefulSets:
- Unveränderliche Netzwerkidentifikation. Alle Pods in einem StatefulSet müssen eindeutige und persistente Netzwerknamen haben.
- Unveränderliche Persistent Volumes. Jeder Pod kann einem oder mehreren Persistent Volumes zugeordnet werden. Es muss gewährleistet sein, dass die Zuordnung zu bestimmten Volumes auch nach einem Neustart noch funktioniert.
- Geordnete Bereitstellung und Skalierung, geordnetes Löschen und Beenden. Für viele Anwendungen ist es äußerst wichtig, dass Pods in einer strikten Reihenfolge erstellt, skaliert, gelöscht und geschlossen werden. Nur so kann die Datenkonsistenz gewährleistet werden.
Headless Service
Headless Services werden zusammen mit StatefulSets verwendet. Stateful-Anwendungen erfordern oft eine direkte Kommunikation zwischen den Pods oder von außerhalb des Clusters zu einem bestimmten Pod. Dies wäre mit Mechanismen wie Load Balancer oder ClusterIP kaum realisierbar, daher wird Cluster DNS verwendet, um die gegenseitige Kommunikation der Pods über den Namen zu ermöglichen.
Beispiel StatefulSet
Hier ein einfaches Beispiel für ein YAML-Manifest für ein StatefulSet zur Bereitstellung einer Prometheus-Instanz:
Headless-Service
apiVersion: v1kind: Servicemetadata: name: prometheus-headless labels: app: prometheusspec: clusterIP: None # macht diesen Service zu einem Headless Service ports: - name: web port: 9090 targetPort: web selector: app: prometheusapiVersion: apps/v1kind: StatefulSetmetadata: name: prometheusspec: serviceName: "prometheus-headless" replicas: 5 selector: matchLabels: app: prometheus template: metadata: labels: app: prometheus spec: containers: - name: prometheus image: prom/prometheus:2.44.0 ports: - name: web containerPort: 9090 volumeMounts: - name: prometheus-data mountPath: /prometheus volumeClaimTemplates: - metadata: name: prometheus-data spec: accessModes: [ "ReadWriteOnce" ] resources: requests: storage: 1Gi
Jobs
Wenn alle oben genannten Controller-Typen für den Start der Pods und deren kontinuierlichen Betrieb vorgesehen sind, besteht der Haupteinsatzzweck der Jobs darin, die einzelnen Tasks in einem Kubernetes-Cluster auszuführen.
Die folgenden drei Szenarien beschreiben am besten die Funktionsweise von Jobs:
- Der Job ist dafür verantwortlich, einen oder mehrere Pods innerhalb des Kubernetes-Clusters zu erstellen.
- Er sorgt auch dafür, dass der Pod oder die Pods ein bestimmtes Programm in einem Container ausführen. Normalerweise sollte dieses Programm bis zu seinem „natürlichen Ende“ laufen. Es sei denn, es wird aufgrund eines Fehlers oder aus einem anderen Grund unterbrochen.
- Anschließend muss der Kubernetes-Job sicherstellen, dass die angegebene Anzahl von Pods ihre Aufgaben erfolgreich abgeschlossen hat. Wenn dies nicht der Fall ist, startet der Job diese Pods neu, um sicherzustellen, dass die Aufgaben abgeschlossen sind.
Jobs können parallel oder seriell ausgeführt werden und erzeugen mindestens einen Pod zur Ausführung der Aufgabe. Nach Beendigung des Jobs werden die Pods automatisch gelöscht.
Beispiel
Hier ist ein Beispiel einer einfachen Wartungsaufgabe. Im Container mein-container werden die Daten aus dem Ordner /var/log gelöscht, wenn sie älter als 7 Tage sind.
apiVersion: batch/v1kind: Jobmetadata: name: log-cleanerspec: template: spec: containers: - name: log-cleaner image: mein-container args: - /bin/sh - -c - find /var/log -type f -mtime +7 -delete restartPolicy: OnFailurerestartPolicy: OnFailure - Die Einstellung OnFailure bedeutet, dass der Container neu gestartet wird, wenn der Prozess mit einem Fehlercode endet.
Je nach Szenario kann das obige Beispiel erweitert werden, um die Fehlertoleranz zu verbessern. Hier einige Parameter:
- backoffLimit - definiert wie oft Kubernetes den Job neu starten soll, wenn er fehlschlägt.
- activeDeadlineSeconds - legt die maximale Zeit in Sekunden fest, die der Job für die Fertigstellung benötigt. Wird die Zeit überschritten, wird der Job abgebrochen und als fehlgeschlagen markiert.
- Completions - gibt die Anzahl der Pods an, die erfolgreich abgeschlossen sein müssen, damit der Job als abgeschlossen gilt. Der Standardwert ist 1
- parallelism - definiert die Anzahl der Pods, die gleichzeitig ausgeführt werden können. Der Standardwert ist 1.
CronJobs
Ein CronJob wird verwendet, um eine bestimmte Aufgabe in regelmäßigen Abständen automatisch auszuführen. Im Gegensatz zu einem "normalen" Job, der nur einmal ausgeführt wird, kann ein CronJob zu einem bestimmten Zeitplan ausgeführt werden. Dieses Konzept ähnelt dem UNIX- oder Linux-CronJob.
Beispiel:
Hier ist ein Beispiel für einen Kubernetes CronJob, der zwei Mal täglich um 8:00 und um 18:00 Uhr einen Job ausführt, um Log-Dateien zu sichern.
apiVersion: batch/v1beta1kind: CronJobmetadata: name: log-backupspec: schedule: "0 8,18 * * *" jobTemplate: spec: template: spec: containers: - name: log-backup image: mein-container args: - /bin/sh - -c - tar czf /backup/logs-$(date +\%Y\%m\%d-\%H\%M\%S).tar.gz /var/log restartPolicy: OnFailure volumes: - name: backup-volume hostPath: path: /mnt/backup volumeMounts: - name: backup-volume mountPath: /backup
schedule: hier wird den Zeitplan für den CronJob definiert. In unserem Fall "0 8,18 * * *" bedeutet, dass der Job die Aufgabe zu Beginn der Stunde "0" um 8:00 und um 18:00 Uhr, jeden Tag "*", in jedem Monat "*" und an jedem Wochentag "*" ausgeführt wird.
restartPolicy: OnFailure - Die Einstellung OnFailure bedeutet, dass der Container neu gestartet wird, wenn der Prozess mit einem Fehlercode endet.
Healthcheck-Objekte
Liveness, Readiness und Startup Probes sind Mechanismen in Kubernetes, um die Gesundheit von Containern in einem Pod zu überwachen und sicherzustellen, dass sie ordnungsgemäß funktionieren.
Liveness Probe
Die Liveness Probe prüft, wie der Name schon sagt, ob ein Container noch läuft. Schlägt die Liveness Probe fehl, wird der Container neu gestartet.
Die Überprüfung des Container-Status kann folgendermaßen funktionieren: Es wird ein HTTP-Request an eine bestimmte URL oder einen bestimmten Port des Containers gesendet, solange eine erwartete Antwort zurückgegeben wird, wird der Container als „lebendig“ markiert. Es kann auch ein bestimmtes Kommando innerhalb des Containers ausgeführt werden.
Hier ist ein Beispiel für eine Liveness Probe, die alle 10 Sekunden eine HTTP-Anfrage an die URL "/healthcheck" sendet:
apiVersion: v1
kind: Pod
metadata:
name: mein-pod
spec:
containers:
- name: mein-container
image: mein-image
livenessProbe:
httpGet:
path: /healthcheck
port: 80
periodSeconds: 10
Readiness Probe
Die Readiness Probe prüft, ob der Container im Pod bereit ist, eingehende Netzwerkanfragen zu empfangen. In diesem Fall ist die Readiness Probe der Liveness Probe sehr ähnlich, jedoch mit einem wichtigen Unterschied. Wenn die Readiness Probe eines Containers fehlschlägt, wird Kubernetes keinen Netzwerkverkehr mehr an diesen Container senden, aber der Container wird nicht neu gestartet.
Ein typischer Anwendungsfall für eine Readiness Probe wäre, dass eine Anwendung eine gewisse Zeit benötigt, um zu starten (z.B. eine Datenbankverbindung zu einem Backend-Server herzustellen), bevor sie Anfragen bearbeiten kann.
Hier ist ein Beispiel für eine Readiness Probe, die alle 5 Sekunden eine TCP-Verbindung zum Port 8080 herstellt:
apiVersion: v1
kind: Pod
metadata:
name: mein-pod
spec:
containers:
- name: mein-container
image: mein-image
readinessProbe:
tcpSocket:
port: 8080
periodSeconds: 10
Startup Probe
Die Startup-Probe prüft, ob die Anwendung im Container erfolgreich gestartet wurde. Diese Probe wird verwendet, wenn die Anwendung eine lange Zeit benötigt (eine lange Initialisierungsphase haben), um zu starten. Wenn die Probe erfolgreich ist, wird davon ausgegangen, dass der Container korrekt gestartet wurde. Wenn die Startup Probe fehlschlägt, wird der Container neu gestartet.
Die Startup Probe kann verhindern, dass Kubernetes den Container ständig neu startet, weil die Liveness Probe fehlschlägt, weil die Anwendung noch nicht initialisiert wurde.
Hier ist ein Beispiel für eine Startup Probe, die eine HTTP-Anfrage an die URL "/startCheck" sendet und den Container als erfolgreich gestartet markiert, wenn eine erfolgreiche Antwort zurückgegeben wird:
apiVersion: v1kind: Podmetadata: name: mein-podspec: containers: - name: mein-container image: mein-image startupProbe: httpGet: path: /startCheck port: 8080 failureThreshold: 30 periodSeconds: 10