Auf dieser Seite finden Sie einen kurzen Überblick über die Splunk Architektur. Splunk Enterprise kann insgesamt aus sechs Komponenten bestehen. Drei wichtigste Komponenten sind: Indexer, Search Head und Forwarder.
Splunk Komponenten
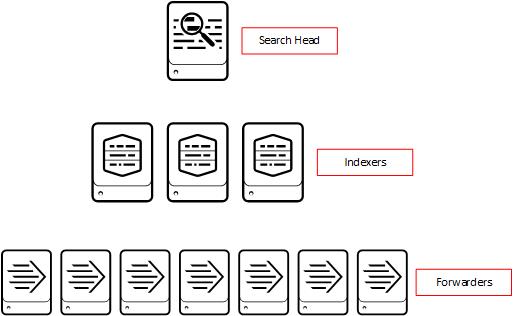
Indexer - verarbeitet die ankommenden Maschinen Daten, speichert diese als Events und durchsucht bei der Aufforderung. Während der Verarbeitung werden die Informationen als Dateien in den Unterordner gespeichert. Die gespeicherten Daten bestehen aus zwei Typen: komprimierte RAW Daten und die Indexer, die drauf zeigen.
Search Head - ermöglicht die Suche innerhalb der indexierten Daten. Search Head nimmt die User-Anfragen auf und leitet an den Indexer weiter. Die zurückgegebenen Informationen werden dem User auf der Konsole präsentiert und können durch die externe Daten (s.g. Knowledge Object) angereichert werden. Die Suche erfolgt auf Basis von Splunk Processing Language. Die Visualisierung von Daten in Form von Reports und Dashboards ist eine weitere Aufgabe des Search Heads.
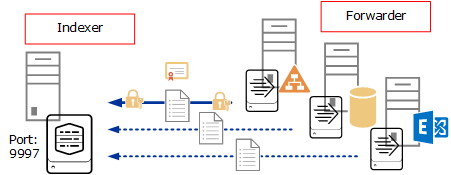
Universal Forwarder - ist eine kleine auf den Zielsystemen installierte Software-Komponente, die die Informationen (Logs) sammelt und an den Indexer weiterleitet. Universal Forwarder ist ein separates Installationspaket.
Deployment Server ist für die Verteilung und Verwaltung von Apps innerhalb des Search Head Cluster zuständig.
License Master - ist der Server, der für die komplette Splunk-Infrastruktur Lizenzen verwaltet. Alle anderen Server werden als Slave konfiguriert. Es ist möglich eine License Pool zu konfigurieren, um die Lizenz-Volumen zu verteilen.
Heavy Forwarder - ist genau wie der Universal Forwarder leitet Heavy Forwarder die Daten an Indexer weiter. Heavy Forwarder leitet keine Rohdaten, sondern bereitet die Daten vor. Für die Installation des Forwarders wird ein Splunk- Installationspaket genutzt.
Deployment-Arten
Aus Architektursicht ist Splunk eine sehr flexible (Pay as You Grow) Lösung. Splunk ermöglicht eine einfache horizontale Skalierung von einer Einzelplatzinstallation (Single-Instance-Deployment) bis zu einer komplexen Infrastruktur (Multi-Instance-Deployment).
Eine Single-Instance-Deployment wie der Name schon sagt beherbergt alle Komponente und Funktionen: Input, Parsing, Indexirung und Suche. Die Single-Instance ist für die kleinen Umgebungen (PoC, Learning) vorgesehen. Es wird empfohlen, immer eine Single-Instance zum Testzwecken einzurichten.
Eine Multi-Instance-Deployment sieht in erster Linien die Trennung zwischen den Indexer und den Search Head. Diese Art von Deployment erlaubt eine Indexierung von bis zu 100 GB pro Tag, bis zu aktiven 100 Benutzer und mehrere Hunderte von Forwarders.
Pipeline
Splunk Pipline ist ein Durchlaufprozess der Daten von Aufnahme und Weiterleitung durch den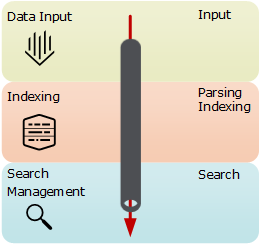 Forwarder bis zur Visualisierung auf der Web-Konsole.
Forwarder bis zur Visualisierung auf der Web-Konsole.
Pipeline besteht aus der drei Ebenen: Date Input, Indexierung, Search Management und aus der vier Segmenten: Input, Parsing, Indexing und Search.
Input - Die RAW-Daten werden in 64K Blöcke zerlegt und mit dem Metadaten-Schlüsseln (Meta Keys) versehen. Die Keys sind immer Source, Host, Sourcetype.
Indexing - Weiter erreichen die Daten die Indexierung-Ebene. Hier finden die Syntaxanalyse und die Indexierung statt. Es werden einzelne Ereignisse erkannt (Parsing) und mit dem Zeitstempel versehen. Weiter werden die Daten komprimiert und auf der Platte geschrieben. Auf der Ebene findet auch die Berechnung der lizenzierten Volumen statt.
Search Ebene verwaltet das benutzerbezogenes Teil. Es ist Schnittstelle zwischen den Benutzern und den Daten.
Indexes - Directory Struktur
Indizes sind die Repositorien wo die indexierten Daten gespeichert werden. Es ist empfohlen den unterschiedlichen Indexes zu verwenden. Dies hat auch mehrere Vorteile. Die Suche wird schneller, da die Volumen kleiner sind. Die Multiplen Indexe ermöglichen eine rollenbasierte Zugriffsteuerung und eine Konfiguration von separaten Aufbewahrungsrichtlinien (Retention Policies) auf Basis von Alter oder Größe.
Speicherorte
Main Index:
C:\Program Files\Splunk\var\lib\splunk\defaultdb
Internal logs und Metrics:
C:\Program Files\Splunk\var\lib\splunk\_internaldb
Store Audit Trails und optionale Audit Informationen:
C:\Program Files\Splunk\var\lib\splunk\audit
System Performance und Ressourcennutzung:
C:\Program Files\Splunk\var\lib\splunk\_introspection
Checkpoint Information:
C:\Program Files\Splunk\var\lib\splunk\fishbucket
Beispiel des Ordnerinhalts
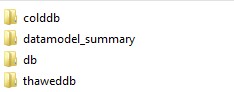
Buckets
Der Splunk-Index besteht aus mehreren Buckets. Bucket sind die Ordner, die die RAW-Daten und die dazugehörigen indexierten Daten beinhalten. Die Daten können sich in einem von fünf möglichen Zuständen befinden: Hot, War, Cold, Frozen, und Thawed. Der Zustand der Daten wird durch Rotationsverfahren beeinflusst.
Hot Buckets (heiße): - beinhalten die aktuellsten Daten, die neu indiziert Daten werden.
Warm Buckets (warme):
Cold Buckets (kalte):
Frozen Buckets (eingefroren):
Thawed Buckets (aufgetaute):