In diesem Blogbeitrag wird primär das Thema der optimalen Verteilung und Nutzung der CPU- und Speicher-Ressourcen in „vSphere with Tanzu“ und den provisionierten Kubernetes Clustern (TKC), behandelt. Die Informationen aus dem Beitrag können sowohl für den Betreiber von Self-Hosted Kubernetes als auch von Managed Kubernetes bei der Planung des Ressourcenbedarfs behilflich sein.
Wie funktionieren Kubernetes Anforderungen und Limits?
Bevor wir zum Thema optimale Ressourcenzuweisung rübergehen, lohnt es sich zuerst die Funktionsweise der Ressourcen-Verwaltung im Kubernetes-Cluster näher zu erläutern.
Bei der Pod-Erstellung besteht die optionale Möglichkeit einige Ressourcen, wie z.B. CPU und Memory (RAM) anzugeben, die ein Pod verwenden darf. Die eingegebenen Informationen dienen dem Kubernetes-Scheduler als Entscheidungsgrundlage zur Platzierung der einzelnen Pods. Der Kubernetes-Scheduler sucht den entsprechenden Worker Node, welcher über die erforderlichen Ressourcen zum Ausführen des Pods (korrekt gesagt, einem Container in einem Pod) verfügt.
Kubernetes beinhalten zwei unterschiedliche Arten der Ressourcenzuweisung:
- Resource requests
- Resource limits
Resource requests - legt die Mindestmenge an RAM/ CPU fest, die für den Container erforderlich ist. Wie bereits erwähnt entscheidet der Kube-Scheduler anhand dieser Informationen auf welchem Worker Node der Pod gestartet werden soll und reserviert die angeforderte Menge der Ressource für diesen Container, damit diese garantiert zur Verfügung stehen.
Wenn auf keinem einzigen Worker Node die verlangten Ressourcen vorhanden sind, wird der Pod erstmal in einen Pending-Zustand versetzt. Erst wenn die angefragten Ressourcen wieder vorhanden sind, wird der Pod ausgeführt.
Resource limits – sorgt dafür, dass der Container seinen Ressourcenverbrauch in Grenzen hält und keine zusätzlichen Ressourcen als vordefiniert, für sich beansprucht, auch wenn solche Ressourcen physikalisch vorhanden sind.
CPU-Limit – wenn für die CPU-Ressourcen keine Grenze gesetzt wird, kann der Container standardmäßig alle vorhandenen CPU-Ressourcen des Worker Nodes für sich beanspruchen. Wenn die CPU-Limitierung auf Namespace-Ebene gesetzt wurde, wird diese Limitierung auf Container automatisch ausgeweitert.
Hier ein kurzes Beispiel dafür, wie Sie Requests und Limits für eine Container-Spezifikation festlegen können:
apiVersion: v1
kind: Pod
metadata:
name: busybox-app
spec:
containers:
- name: busybox
image: busybox
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"
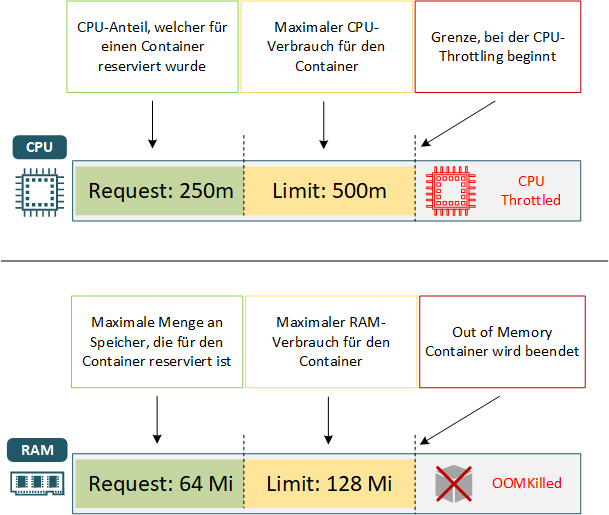
Der Request-Wert ist immer kleiner als der Limit-Wert.
Einheiten
Die CPU-Anforderungen werden in Millicores (auch milliCPU genannt) („m“) oder in Cores festgelegt, wobei 1000 Millicores = 1 vCPU oder 1 physische CPU Core entspricht. Der minimale Wert beträgt 0.1 Core.
250m auf dem oberen Bespiel bedeutet, dass die ¼ einer CPU aufgefordert wurde und die Limitierung auf 500m gesetzt ist.
Die Memory-Anforderungen werden in Bytes gemessen. Für die Eingabe der Speicher-Ressourcen können unterschiedlichen Suffixe (einstellige und zweistellige) verwendet werden (z.B. Mi bedeutend Mebibyte und entspricht 1,04858 MB, oder 128 MebiByte ist gleich zu 135 Megabyte (MB)).
Limits-Überschreitung
Wenn der Verbrauch von CPU-, und Speicher-Ressourcen näher an seine Grenzen kommt, werden folgende Mechanismen eingesetzt, um den Verbrauch von Ressourcen zu reduzieren: OOM und CPU Throttling.
OOM (Out-Off-Memory)
Wenn der Container versucht über die erlaubte Grenze der zugewiesenen RAM hinauszugehen, wird dieser von Kubelet (Out-Off-Memory-Killer, Exit-Code 137) beendet und im optimalen Fall (ausreichende Ressourcen sind vorhanden) neu gestartet. Aus diesem Grund empfiehlt es sich, realistische Limits (erfahrungsbasierte Werte) zu setzen und dadurch die Stabilität des Systems zu erhöhen. Die Pods können auch beendet werden, wenn Pods mit hoher Priorität mehr Speicher benötigen.
CPU Throttling
Wenn ein Pod die Limit überschreitet, wird die CPU-gedrosselt. Die Überschreitung der CPU-Limits wird im Vergleich zur Memory-Überschreitung weniger restriktiv gehandelt, da der Container in diesem Fall nicht gekillt wird.
Resource Quotas
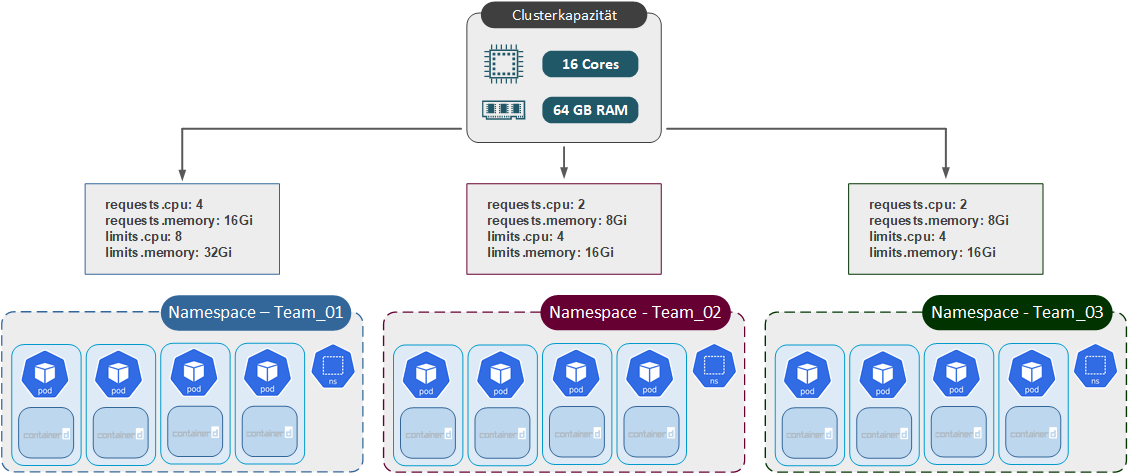
Die Verwendung von Resource Quotas bietet die Möglichkeit, die Nutzung der CPU- und Speicher-Ressourcen auf Namespace-Ebene einzuschränken. Diese Technologie (Kubernetes Objekt: ResourceQuota) ist für den UseCase vorgesehen, wenn unterschiedlichen Teams einen Kubernetes Cluster teilen. So wird die angemessene Verteilung ermöglicht. Grundsätzlich können Sie mit Resource Quotas auch die Nutzung den anderen Objekten verwenden. Dies wird aber in diesem Betrag nicht behandelt.
Hier ist ein Bespiel der ResourceQuotas- Konfiguration, welche für jeden Namespace erstellt werden muss:
apiVersion: v1
kind: ResourceQuota
metadata:
name: team-alpha
spec:
hard:
requests.cpu: 2
requests.memory: 2Gi
limits.cpu: 4
limits.memory: 4Gi
requests.cpu: 2 -
requests.memory: 2Gi
limits.cpu: 4
limits.memory: 4Gi
- requests.cpu / requests.memory - die Summe aller CPU- / Sprecher-Anforderungen darf nicht höher sein als der hier definierte Wert.
- limits.cpu / limits.memory - die hier eingegebene Grenzwerte dürfen nicht überschritten werden.
Falls die Gesamtkapazität eines Clusters kleiner ist als die Summe aller Kontingente der Namespaces, kann es zu Ressourcenkonflikten kommen, die nach Prinzip „First Come First Serve“ gelöst werden.
Die Verwendung von ResourceQuota kann sowohl gemeinsam mit den Requests/Limits auf der Pod-Ebene als auch separat genutzt werden.
Monitoring
Es ist äußerst wichtig, die zugewiesenen Ressourcen zu überwachen, um anschließend die optimale Menge an CPU und RAM zuweisen zu können.
Folgende Metriken können nützlich sein (Beispiel):
- CPU % by Node
- Memory % by Node
- CPU Quota used
- Memory Limit used
- CPU Requests vs. Allocatable
- Memory Requests vs. Allocatable
Wenn die reale Ressourcennutzung wesentlich geringer ist als die Requests, werden wertvolle Ressourcen verschwendet. Wenn die Ressourcennutzung höher als geplant ist, sind die Leistungsprobleme vorprogrammiert und dazu auch die unzufriedenen Kunden zu Folge.
VMware
Größe der virtuellen Maschine für Worker Nodes
VMware bietet insgesamt 16 vordefinierte Klassen virtueller Maschinen unterschiedlicher Größen, die die Menge an vorhandenen CPU- und Arbeitsspeicherressourcen vorgeben.
VM-Klassen: Guaranteed oder Best-effort
Wenn Sie einen Tanzu Kubernetes Cluster erstellen wollen, haben Sie die Wahl aus zwei möglichen Optionen des QoS (Quality of Service): guaranteed und best-effort
- Guaranteed - in diesem Fall werden die CPU-, und Arbeitsspeicher- Ressourcen auf vSphere-Ebene für die VMs reserviert.
- Best-Effort – in der Best-Effort- Klasse ist dies nicht der Fall, die erstellten VMs werden von der Ressourcen-Knappheit nicht verschont.
Die Reservierung von Ressourcen garantiert jedoch keine hohen CPU-Performancewerte, da CPU-Auslastung auch aus den anderen (unten beschriebenen) Gründen degradiert werden könnte. Da die Überbuchung von Speicherressourcen grundsätzlich vermieden werden sollte, werden in den Guaranteed VM-Klassen auch Mechanismen wie Memory- Swapping und Memory-Ballooning nicht zum Einsatz kommen.
Um die Stabilität des Systems zu gewährleisten, sollte in der Produktionsumgebung eine guaranteed-VM-Klasse verwendet werden. Es ist selbstverständlich, dass die ESXi-Hosts in einen vSphere-Cluster über ausreichende CPUs- und Arbeitsspeicher-Ressourcen verfügen sollen, um die optimale Performance garantieren zu können.
Um die Stabilität des Systems zu gewährleisten, sollte in der Produktionsumgebung eine guaranteed-VM-Klasse verwendet werden. Es ist selbstverständlich, dass die ESXi-Hosts in einen vSphere-Cluster über ausreichende CPUs- und Arbeitsspeicher-Ressourcen verfügen sollen, um die optimale Performance garantieren zu können.
VM-Klassen
Die Größenauswahl erstreckt sich von ganz kleinen VMs (xsmall*: 2 vCPU, 2 GB RAM) bis zum 8xlarge VMs, die mit 32 vCPU und 128 GB RAM ausgestattet werden. *Die Nutzung von xsmall und small wird von VMware nicht empfohlen.
Es besteht selbstverständlich die Möglichkeit eine eigenen VM-Klasse anzulegen, da die vorhandenen Klassen nicht anpassbar sind.
| Klasse | CPU | RAM | Reserviert |
| guaranteed-8xlarge | 32 | 128 | ja |
| best-effort-8xlarge | 32 | 128 | nein |
| best-effort-8xlarge | 16 | 128 | ja |
| best-effort-4xlarge | 16 | 128 | nein |
| guaranteed-2xlarge | 8 | 64 | ja |
| best-effort-2xlarge | 8 | 64 | nein |
| guaranteed-xlarge | 4 | 32 | ja |
| best-effort-xlarge | 4 | 32 | nein |
| guaranteed-large | 4 | 16 | ja |
| best-effort-large | 4 | 16 | nein |
| guaranteed-medium | 2 | 8 | ja |
| best-effort-medium | 2 | 8 | nein |
| guaranteed-small | 2 | 4 | ja |
| best-effort-small | 2 | 4 | nein |
| guaranteed-xsmall | 2 | 2 | ja |
| best-effort-xsmall | 2 | 2 | nein |
Quelle: VMware
Die optimale Größe und der erwartete Ressourcenverbrauch für die Worker Nodes lässt sich nur anhand der vorherige Evaluierung und der Überwachung von entsprechenden Metriken feststellen.
CPU-Overcommitting (auch Over-Subscription)
Bei der Bereitstellung eines Clusters kann es vorkommen, dass die Summe aller Ressourcenanforderungen größer ist als dem Cluster tatsächlich zur Verfügung stehen. In solchen Fällen sprechen wir über "Overcommitting" (Überbuchung).
Die Überbuchung von Ressourcen ist eine Möglichkeit, diese optimal und kosteneffizient zu verwenden. Aus technischer Sicht ist eine CPU-Überbuchung die Aufteilung von physischen CPUs in virtuelle CPUs. Sobald ein Verhältnis (Ratio) von 1:1 zwischen den zugewiesenen vCPUs und den physischen verfügbaren CPUs überschritten wird, spricht man von CPU-Überbuchung. Z.B. ein Verhältnis 3:1 bedeutet, dass drei vCPUs einem physischen CPU-Core zugewiesen werden. Verständlicherweise je höher (4:1, 6:1 usw.) das Verhältnis ist, desto höher ist die Auslastung der physischen CPU.

Die auf dem Diagramm abgebildete ESX-Infrastruktur dient ausschließlich zur Veranschaulichung des CPU-Overcommitments und darf auf keinen Fall als ein Beispiel der VM-Verteilung verstanden werden. Stichwort: Ressourcenverteilung in einem Cluster (HA-Failover, Distributed Resource Scheduler, N+1 usw.).
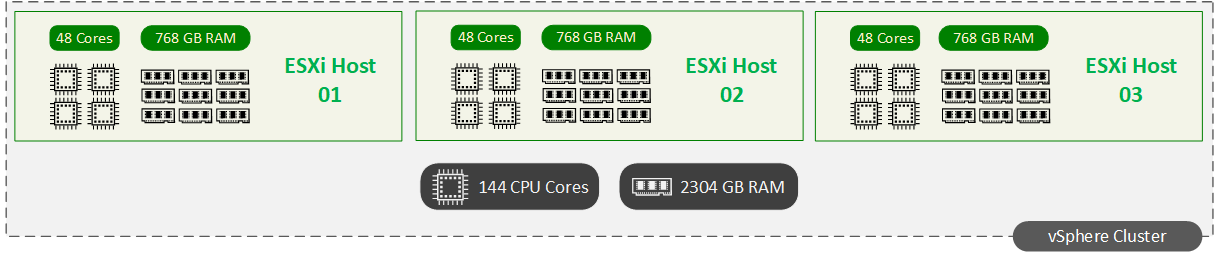
Anschließend wird nur die Gesamtzahl der physischen Kerne in allen Servern des Clusters als Berechnungsgrundlage gesehen. Die Gesamtkapazität der abgebildeten ESX-Hosts beträgt z.B. 144 CPU Cores und 2,25 TB RAM.
Es ist wichtig in Erinnerung zu behalten, dass in einer Produktionsumgebung eine ausreichende Anzahl an ESXi-Host bereitgestellt werden muss, um geplante (Wartungsarbeiten) und ungeplante Serverausfälle ohne jegliche Performanceverluste überstehen zu können. Die Guaranteed-VMs müssen auch dann funktionieren, wenn einigen ESXi-Hosts nicht mehr zur Verfügung stehen.
Welche Overcommitting-Ratio ist optimal?
Diese Frage kann nur mit der „klassischen“ IT-Antwort “it depends“ beantwortet werden. Wenn in anderen Bereichen über die Jahre Erfahrungswerte gesammelt wurden (wie z.B. im Bereich Virtualisierung), gibt es im Bereich Kubernetes keine pauschalisierte Antwort, da die gehostete Applikationen und die Infrastruktur-Bedingungen sehr unterschiedlich sind.
Das optimale Verhältnis lässt sich ausschließlich in einem Test-Betrieb inkl. enger Zusammenarbeit mit dem Entwicklerteam feststellen. Nur auf diese Art und Weise lässt sich die tatsächliche Arbeitslast der einzelnen Anwendung realistisch analysieren (besonders wenn es um die CPU-Spitzenauslastung geht), bevor man zu wenig oder zu viele Ressourcen einer virtuellen Maschine (Worker Node) zuweist.
Wenn die CPU-Auslastung nachweislich niedrig ist, lassen sich die CPUs überbelegen, um die effizientere Nutzung der Ressourcen zu erreichen. Das CPU-Überbuchung-Ver¬hält¬nis können Sie anhand empirischer Tests festlegen. Ob es anschließend 2:1 oder 4:1 wird, lässt sich pauschal nicht sagen. (z.B. für Citrix-Workload können Sie mit 4.1 starten)
Hyperthreading
Nach der Aktivierung (im BIOS) des Hyperthreadings wird die Anzahl der angezeigten CPU-Cores optisch verdoppelt, die physischen Cores werden zu logischen Cores „umgewandelt“. Die Leistungsvorteile von Hyperthreading halten sich aber in Grenzen. Es kann zwar die von Intel versprochene effiziente CPU-Auslastung in einem gewissen Grad (je nach Workload bis zu 30%) erreicht werden, wird aber nie kann von einer Verdoppelung die Rede sein.
Die Hyperthreading-Technologie kann (und soll) zwar aktiviert werden, aber bei der Planung der Ressourcen-Bedarfs völlig ignoriert werden.
Überwachung der CPU Auslastung
Die Überwachung (z.B. mit esxtop in ESX-Hosts) der folgenden Hypervisor-Metriken (besonders CPU Ready und CPU Readiness) kann bei der Feststellung des realen CPU-Bedarfs sowie des optimalen Overcommitment-Verhältnis helfen:
- vCPU Usage (Auslastung) (%)
- CPU Queue Length (Warteschlangenlänge)
- CPU Ready Time
- CPU Readiness
Zusätzlich zur allgemeinen Überwachung ist es sinnvoll, die Ressourcennutzung unter Last zu bringen, um den Verbrauch unter Spitzenlasten zu bewerten.
Memory-Overcommitting
Es ist grundsätzlich eine schlechte Idee die Arbeitsspeicher-Ressourcen zu überbuchen und sollte in einer Produktionsumgebung nie ernsthaft in Betracht gezogen werden, obwohl es die technischen Mittel dafür gibt.
Anzahl der zugewiesenen vCPUs
Einen weiteren Punkt, welcher unbedingt mit dem Entwicklerteam abgesprochen werden muss, ist die erforderliche Anzahl der vCPUs für die bereitgestellte Applikation. Je nachdem wie viele vCPUs eine Applikation benötigt, werden auch die Worker Nodes dementsprechend konfiguriert. Am besten lässt sich das Problem an folgendem Beispiel erklären: wenn für einen Worker Node die sechs vCPUs erforderlich sind, muss der Hypervisor darauf warten, bis dafür die benötigten sechs pCPUs verfügbar werden. Wenn der Hypervisor ausgelastet ist, dauert es wesentlich länger, bis ein Time Slot für sechs vCPUs verfügbar ist, als z.B. für den Worker mit zwei oder vier vCPUs der Fall wäre.
NUMA-Nodes
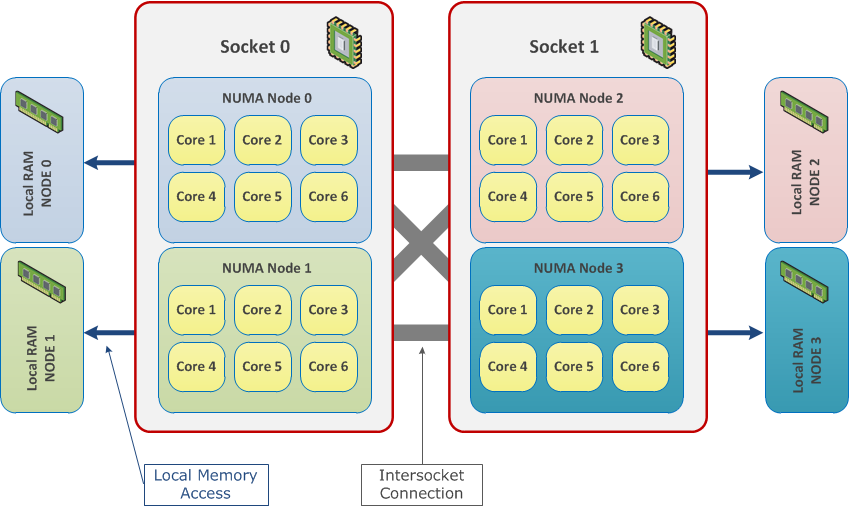
Eine Diskussion über eine optimale Ressourcen-Verteilung wäre ohne eine kurze Beschreibung der NUMA- Architektur nicht vollständig gewesen.
Beim NUMA (Non-Uniform Memory Access) handelt es sich um die Architektur für Multiprozessor-Computersysteme. Die CPUs werden direkt an einen eigenen lokalen Speicherbereich (RAM) angeschlossen. Dadurch wird ein schneller Prozessorzugriff auf den lokalen Arbeitsspeicher ermöglicht. Alle CPUs in einem physischen System und der dazugehörige lokale RAM werden in NUMA-Nodes aufgeteilt. In diesem Fall greifen die CPUs auf das lokale RAM innerhalb dieses NUMA-Knotens. Die CPUs eines NUMA-Nodes können selbstverständlich auf die Speicherbereiche eines anderen Nodes zugreifen. Solche Zugriffe werden allerdings weniger effizient sein. Infolgedessen kann die maximale Performance erst dann erreicht werden, wenn die Anzahl der Zugriffe auf die Speicherbereiche der „fremden“ NUMA-Nodes minimiert wird.
Bevor Sie die Worker-Nodes einer bestimmen Größe erstellen, lohnt es sich die Server-Dokumentation zu verifizieren, um dafür zu sorgen, dass die Anzahl der CPUs und RAMs in den Grenzen eines einzelnen NUMA-Nodes bleibt.
Fazit – Right sizing
Wie Sie anhand der oberen Ausführungen bereits wissen, gibt es kein „Rezept“ der optimalen Nutzung der Hardware-Ressourcen. Nur durch die Überwachung und anschließende Bewertung der Ressourcennutzung der gehosteten Applikationen lässt sich eine optimale Gesamtmenge der CPU- und Speicher-Mengen sowie die Anzahl der Worker Nodes inkl. passender VM-Klassen bestimmen.
Vielen Dank, dass Sie sich die Zeit genommen haben, den Artikel bis zum Ende gelesen.