Das Thema „Optimale Ressourcennutzung“ wäre ohne die verschiedenen Skalierungsmethoden zu beschreiben nicht wirklich vollständig. Dieser Beitrag gibt einen Überblick über die Autoscaling Methoden die im Bereich Kubernetes zum Einsatz kommen.

Was ist Skalierung?
Als Skalierung im Allgemeinen wird die Erhöhung oder Reduzierung vorhandener Ressourcen bezeichnet.
Es existieren der zwei Arten der Skalierung:
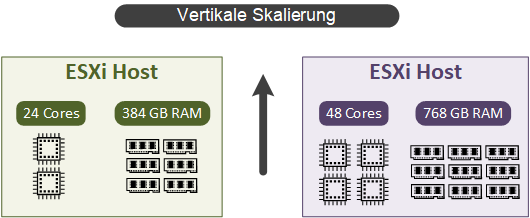
Vertikale Skalierung (scaling up) – die vertikale Skalierung wird durch das Hinzufügen von zusätzlichen Hardware-Ressourcen erreicht. Wie auf dem unteren Bild dargestellt, wurde der existierende Server mit mehr CPU und RAM ausgestattet. Auf solcher Art und Weise lassen sich sowohl physische als auch virtuelle Ressourcen erweitern.
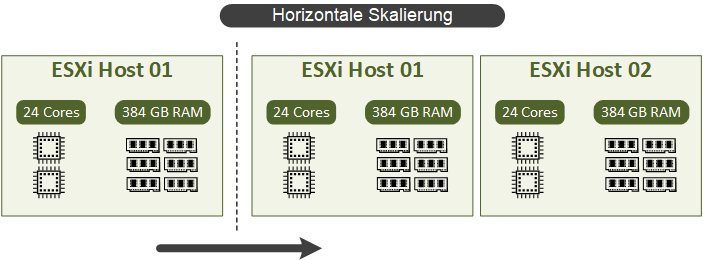
Horizontale Skalierung (scaling out) – eine horizontale Skalierung unterscheidet sich von der vertikalen darin, dass die bestehenden Komponenten nicht angepasst werden, sondern neue Instanzen der Systeme (VMs/Instanzen/Knoten) hinzugefügt werden.
Die Vertikale/ Horizontale Skalierung bezieht sich selbstverständlich nicht nur auf CPU- und Arbeitsspeicher-Ressourcen, sondern auch auf andere Eigenschaften, wie zum Beispiel Storage oder Netzwerk.
Horizontale vs. Vertikale Skalierung
Welche der beiden Methoden am besten geeignet ist, lässt sich pauschal nicht beantworten und ist von mehreren Faktoren abhängig. Moderne Systeme, die eine Microservice-Architektur mit Containern verfolgen, sind meist auf eine horizontale Skalierung ausgelegt, während ältere monolithische Systeme am meisten von einer vertikalen Skalierung profitieren.
Der weitere Vergleich bezieht sich ausschließlich auf die virtuelle Infrastruktur (die Vorteile/Nachteile von physischen Servern sind definitiv anders) und zeigt, dass sowohl horizontale als auch vertikale Skalierung ihre eigenen Vorteile und Nachteile haben.
Horizontale Skalierung
Vorteile
- keine Ausschaltung von VMs notwendig, um zusätzliche Ressourcen hinzuzufügen.
- mehrere VMs für den gleichen Workload erhöhen die Ausfallsicherheit.
- bei Bedarf werden die unnötigen VMs ausgeschaltet, wodurch die Kosteneffizienz steigt.
- die Lastspitzen können durch eine vollständige Automatisierung abgefedert werden.
Nachteile
- die Nachteile sind in gewissermaßen von der individuellen Situation abhängig wie z.B.:
- Sicherung
- Lizensierung
- hohe Komplexität, da eine vollständige Automatisierung benötigt wird.
Vertikale Skalierung
Vorteile
- weniger Wartungsintensiv.
- benötigt weniger Lizenzen, da die Anzahl der ausgeführten Instanzen gleichbleibt.
Nachteile
- bei einem Ausfall sind mehrere Nutzer gleichzeitig betroffen.
- extrem unflexibel.
Was ist Kubernetes Autoscaling?
Kubernetes Autoscaling ermöglicht eine dynamische Anpassung an steigenden oder sinkenden Ressourcen-Bedarf durch horizontales und vertikales Skalieren von verschiedenen Ressourcen.
Im Gegensatz zu dem „legacy“ Scaling, orientiert sich das Kubernetes Autoscaling nicht auf die Skalierung von physischen oder virtuellen Maschinen, sondern hat eine weitere Abstraktionsebene zu bedienen. Beim Kubernetes Autoscaling stehen die Applikationen und architekturbedingt darunterliegenden Pods im Fokus.
Da die Kubernetes-Infrastruktur überwiegend in der Cloud genutzt wird, hilft die automatische Skalierung von Kubernetes die Kosten zu optimieren, indem ein Cluster je nach aktuellen Bedarf dynamisch aufwärts und abwärts skaliert wird.
Autoscaling-Funktionen für Kubernetes
In Kubernetes gibt es drei Autoscaling-Funktionen.
- Vertical Pod Autoscaler (VPA) - erhöht oder reduziert CPU- und Speicher-Ressourcen in Pod
- Horizontal Pod Autoscaler (HPA) - fügt neue Pods hinzu oder entfernt diese
- Cluster Autoscaler - kann Clusterknoten hinzufügen oder entfernen
Vertical Pod Autoscaler (VPA)
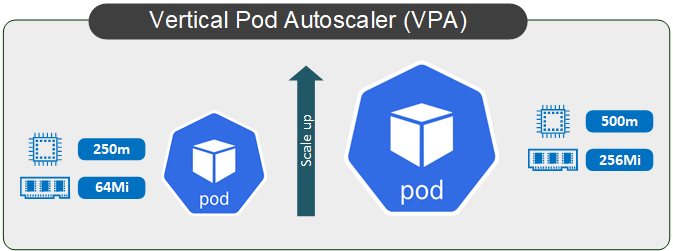
Wie bereits oben erwähnt, basiert VPA auf demselben Prinzip wie „klassische“ vertikale Skalierung, nämlich das Hinzufügen oder Entfernen von Ressourcen (z. B. CPU oder Arbeitsspeicher) zu einem Pod. Man konnte VPA als eine Weiterentwicklung von den in Kubernetes üblichen Requests und Limits betrachten, allerdings mit einem wesentlichen Unterschied: Die Requests werden automatisch anhand der Verhaltensbeobachtung (etwa 5 Minuten) und einer anschließenden Bewertung aktualisiert.
Für die „technische“ Umsetzung ist ein Kubernetes-Objekt namens VerticalPodAutoscaler zuständig, zu dem noch drei Komponenten gehören:
Der Recommender ist die Kernkomponente des VPAs. Der Recommender dient zur Überwachung den historischen und aktuellen Ressourcenverbrauch und der Berechnung darauf basierenden CPU- und Memory-Requests.
Link: https://github.com/kubernetes/autoscaler/blob/master/vertical-pod-autoscaler/pkg/recommender/
Der Updater ist für die Umsetzung von Recommender berechneten Empfehlungen zuständig. Der Updater erstellt neue Pods und beendet jene, welche aktualisiert werden müssen. Die tatsächliche Aktualisierung wird aber vom Vertical Pod Autoscaler Admission Plugin durchgeführt.
Horizontal Pod Autoscaler (HPA)
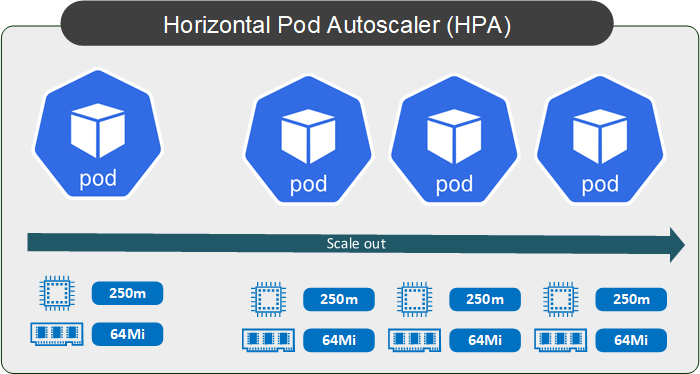
Wie auf dem Bild zu sehen ist, unterscheidet sich HPA von VPA durch die Erhöhung oder Reduzierung der Pod-Anzahl und nicht durch die Anpassung deren Eigenschaften.
HPA ist im Vergleich zum VPA wesentlich flexibler, da durch das Hinzufügen / Entfernen von Pods eine kosteneffiziente und performante Umgebung gebaut werden kann. Ein weiterer, eher hypothetischer Vorteil ist die Möglichkeit, die Performance-Engpässe im Bereichen Storage I/O und Netzwerk abzufedern. Wobei die Entscheidung weiteren Pods zu starten, wird ausschließlich auf Basis von CPU- und Arbeitsspeicher-Metriken getroffen. Die realen Engpässe bei IOPS, Netzwerk und Storage werden nicht berücksichtigt.
Die einzige Voraussetzung bei der Nutzung von HPA ist, dass die verwendeten Applikationen unter Beachtung der horizontalen Skalierung entwickeln sind und die parallele Ausführung mehreren Instanzen unterstützen.
HPA Komponenten
Bei dem Aufbau vom HPA werden mehreren Komponenten zum Einsatz kommen: HPA, cAdvisor, Metrics API, API Service und Mertics Server.
Auf jedem Node ist eine Komponente namens cAdvisor eingebaut (als Teil von kubelet) und dient zur Überwachung der Ressourcenauslastung der laufenden Container. cAdvisor sammelt mehrere interne Metriken in einem Node, die aber von keinem Tool genutzt werden.
Link: https://github.com/google/cadvisor
Die vom cAdvisor gesammelten Metriken werden von einem weiteren Tool namens Mertics Server aggregiert. Der Metrics Server wird über die Metrics API für HPA und VPA zur Verwendung bereitgestellt.
Link: https://github.com/kubernetes/metrics
Der Metrics Server ist eine separate Komponente und wird nicht bei der Cluster-Installation mitinstalliert. Die Installation muss unter Beachtung einiger Voraussetzungen durchgeführt werden. Der Metrics Server läuft als Pod in dem Kubernetes-Cluster und sammelt in regelmäßigen Abständen (standardmäßig 60 Sekunden) die Metriken (CPU und Speicher) von den Nodes. Die gesammelten Metriken werden nicht aufbewahrt und sind zur sofortigen Verwendung bestimmt.
Link: https://github.com/kubernetes-sigs/metrics-server
HPA-Versionen
Es gibt zwei HPA-Versionen: v1 und v2. Die erste HPA-Version (autoscaling/v1) hat eine sehr begrenzte Konfigurationsmöglichkeit und ist ausschließlich auf der durchschnittlichen CPU-Auslastung basiert.
Die zweite Version (autoscaling/V2beta1 und autoscaling/V2beta2) unterstützt die Verwendung von mehreren Metriken. Diese Metriken können auch vom Benutzer definiert oder aus externen Quellen stammen.
Cluster Autoscaler
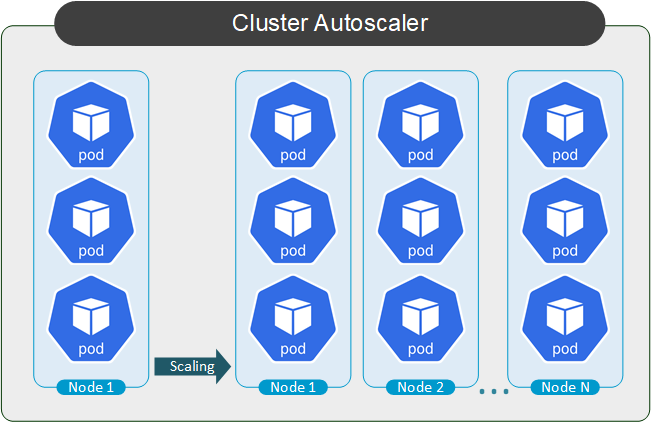
Cluster Autoscaler ermöglicht die automatische Skalierung des Clusters selbst, indem die Anzahl der Knoten erhöht oder verringert wird.
Es kann zu einer Situation kommen, dass trotz einer dynamischen Verteilung von Ressourcen, alle zugewiesenen Ressourcen verbraucht sind und keine weiteren Pods in den vorhandenen Worker Nodes gestartet werden können. In diesem Fall gibt es nur eine Möglichkeit bestehende Engpässe zu beseitigen: die Anzahl der Worker Nodes erhöhen.
Im Gegensatz zu den zwei anderen Skalierungsmethoden, ist Cluster Autoscaler kein Bestandteil des Kubernertes Clusters, da Kubernetes keine Mechanismen hat eine automatische Erstellung und Entfernung von virtueller Maschinen zu ermöglichen. Der Cluster Autoscaler ist eine „typische“ Komponente des Managed Kubernetes bei den Cloud Providern.
Fazit
Ich hoffe, dass die Inhalte des Beitrages für Sie sinnvoll waren, um den Überblick über die verschiedenen Methoden zu erhalten. Da HPA wesentlich öfter als VPA zum Einsatz kommt, eine die dynamische Skalierung der Anwendungen auf der Grundlage verschiedener Metriken bietet, lohnt es sich mit der Funktionsweise in einem weiteren Beitrag näher zu beschäftigen.