Dies ist der dritte Teil des Artikels über die Architektur von Kubernetes. Dieser Beitrag konzentriert sich hauptsächlich auf die Beschreibung der Methoden, die zur Organisation von Objekten in Kubernetes verwendet werden: Namespaces, Labels und Annotations.
- Teil 5 - Taints & Tolerations, NodeSelector, Affinity
- Teil 4 - Workload Objekte
- Teil 2 - API-Server, API Objects
- Teil 1 - Überblick über die Kubernetes Architektur
Kubernetes Namespace
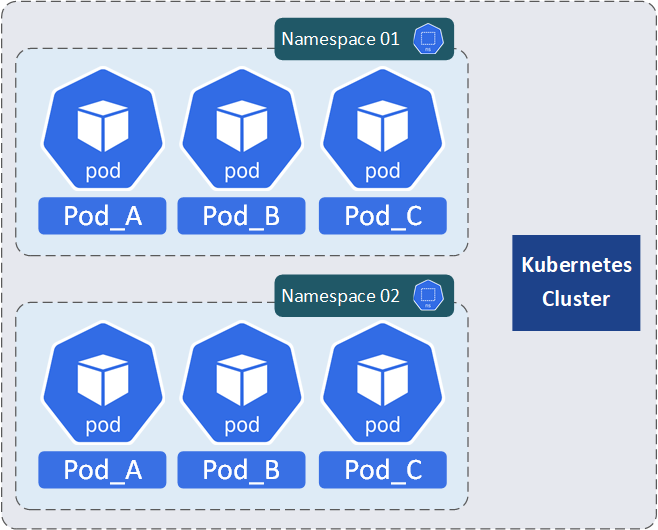
Namespaces sind sicherlich die wichtigste Methode, um Objekte in einem Kubernetes-Cluster in logische Einheiten zu organisieren. Die Verwendung von Namespaces ermöglicht die Aufteilung eines physischen Clusters in mehrere virtuelle Cluster. (Kubernetes-Namespaces hat nichts mit dem Konzept des Namespace des Linux-Betriebssystems zu tun)
Die Einsatzszenarien von Namespaces lassen sich grob in vier Bereiche unterteilen:
- Isolierung
- Ressourcenverwaltung
- Zugriffssteuerung
- Namenstrennung
Isolierung
Die Isolierung ist wahrscheinlich der Hauptgrund für die Verwendung von Namespaces in einem Kubernetes-Cluster. Die Isolierung bezieht sich sowohl auf die Sichtbarkeit als auch auf die Ressourcennutzung.
Alle in einem Namespace vorhandenen Ressourcen sind standardmäßig* nur innerhalb dieses Namespace sichtbar. Das bedeutet, dass z.B. Pods, Services, Volumes und andere Ressourcen, die in einem Namespace erstellt wurden, nicht direkt von einem anderen Namespace aus sichtbar oder zugänglich sind.
* es gibt eine Reihe von Möglichkeiten, die Sichtbarkeit von Ressourcen zwischen Namespaces zu implementieren: Ingress Controller, Service Mesh, RBAC, Kubernetes Network Policies, Cluster-scope Ressourcen. Nicht alle diese Tools und Konzepte haben direkt mit der "Sichtbarkeit" von Ressourcen zu tun haben, sondern eher mit Zugriffskontrolle, Routing und Kommunikation.
Ressourcenverwaltung
Aus technischer Sicht können Namespaces verwendet werden, um Ressourcenquoten zu definieren, die in einem Namespace verbraucht werden können. Durch die Verwendung von Namespace-basierten Ressourcenquoten kann verhindert werden, dass eine Anwendung alle Ressourcen des Clusters für sich beansprucht und dadurch andere Anwendungen beeinträchtigt.
Es gibt eine Vielzahl von Ressourcen, deren Verbrauch begrenzt werden kann. Hier sind einige Beispiele:
| Ressourcenart | Begrenzt die ... die in einem Namespace erstellt oder beansprucht werden können. |
|---|---|
| pods | Gesamtzahl der Pods |
| services | Gesamtzahl der Services |
| persistentvolumeclaims | Gesamtzahl der PersistentVolumeClaims |
| secrets | Gesamtzahl der Secrets. |
| configmaps | Gesamtzahl der ConfigMaps |
| requests.cpu | Gesamtmenge an CPU-Zeit |
| requests.memory | Gesamtmenge an Speicher |
| limits.cpu | maximale Menge an CPU-Zeit |
| limits.memory | maximale Menge an Speicher |
| requests.ephemeral-storage | Gesamtmenge an temporärem Speicherplatz |
| limits.ephemeral-storage | maximale Menge an temporärem Speicherplatz |
Für die technische Umsetzung ist der Kubernetes-Objekttyp (Kind) „ResourceQuota“ zuständig. Hier ist ein Beispiel wie die Anzahl der Pods in einem Namespace begrenzt wird:
apiVersion: v1kind: ResourceQuotametadata: name: pod-quota namespace: mein-namespacespec: hard: pods: "15"
Zugriffssteuerung
Die Namespaces übernehmen die Rolle der Sicherheitsgrenze für die rollenbasierte Zugriffskontrolle. Wir können auf der Basis von Namespaces einschränken, wer auf welche Ressourcen innerhalb eines Clusters zugreifen darf. Eine Ressource kann unter demselben Namen in mehreren Namespaces existieren. (RBAC kann sowohl auf Namespace-Ebene als auch auf Cluster-Ebene angewendet werden.)
Namenstrennung
Die Namespaces können auch als eine Benennungsgrenze verwendet werden, wobei die Namen der Ressourcen nur innerhalb eines Namespace, nicht aber im gesamten Cluster eindeutig sein müssen.
Vordefinierten Namespaces
Nach der Installation eines neuen Kubernetes-Clusters stehen die folgenden vordefinierten Namespaces zur Verfügung:
| Namespace | Beschreibung |
|---|---|
| default | Dies ist der Standard-Namespace, in dem Objekte erstellt werden, wenn kein anderer Namespace angegeben ist. |
| kube-system | Dieser Namespace ist für Objekte reserviert, die vom Kubernetes-System selbst erstellt werden. |
| kube-public | Dieser Namespace ist für Ressourcen vorgesehen, die für alle Benutzer öffentlich sichtbar und lesbar sein sollen. |
| kube-node-lease | Dieser Namespace enthält Lease-Objekte, die mit jedem Knoten verbunden sind. |
Kubectl-Befehle
kubectl get all --all-namespaces – zeigt alle Ressourcen in allen Namespaces anzeigen möchten
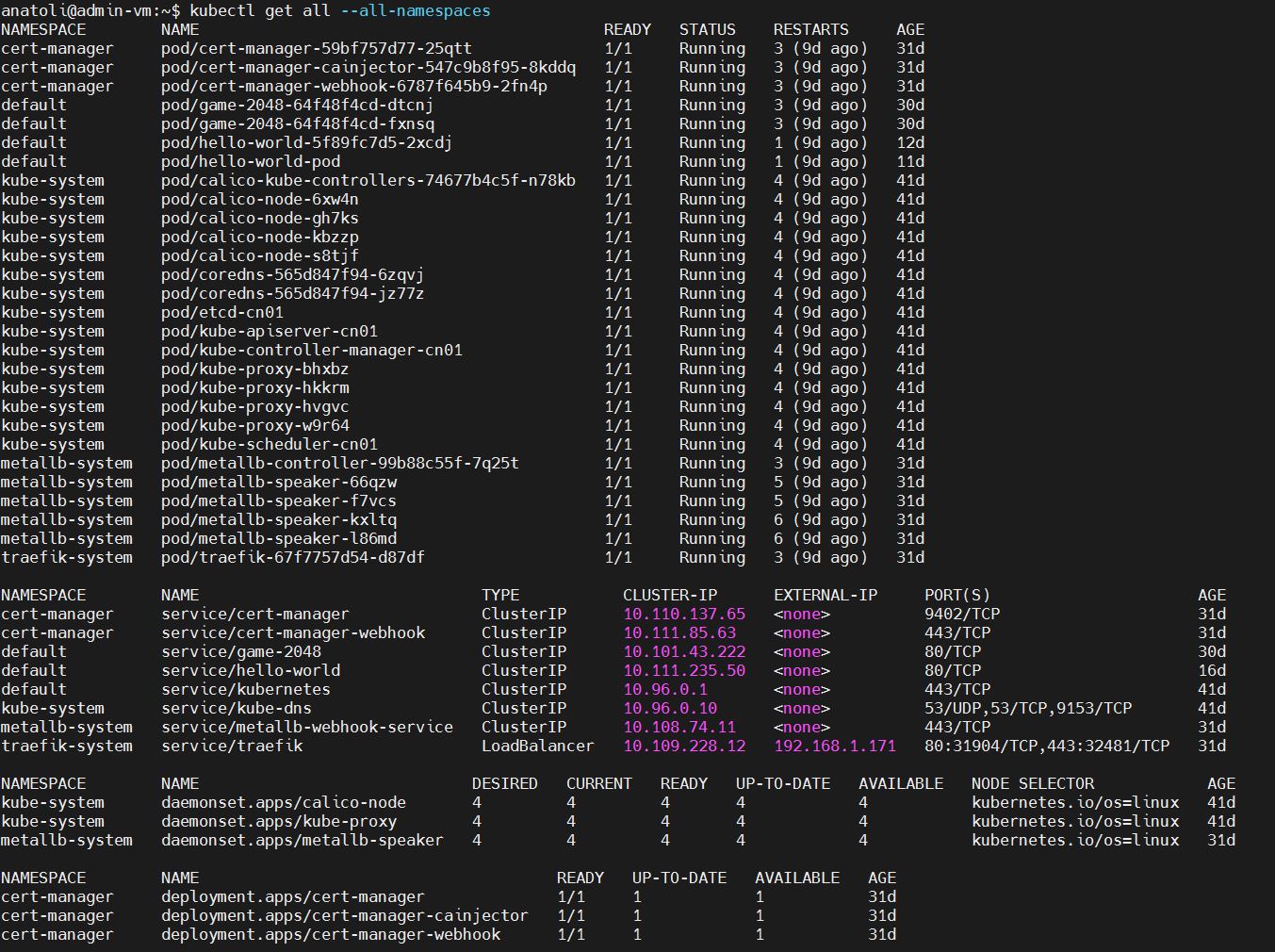
kubectl-Beispiele zur Verwaltung der Namespaces:
kubectl get namespaces - Liste aller Namespaces anzeigen
kubectl create namespace <namespace-name> - Namespace erstellen
kubectl delete namespace <namespace-name> - Namespace löschen
kubectl config set-context --current --namespace=<namespace-name> - Aktuellen Namespace ändern
kubectl describe namespace <namespace-name> - Informationen über einen Namespace anzeigen
kubectl get <resource> -n <namespace-name> - Ressourcen im Namespace anzeigen
Was ist Kubernetes Labels?
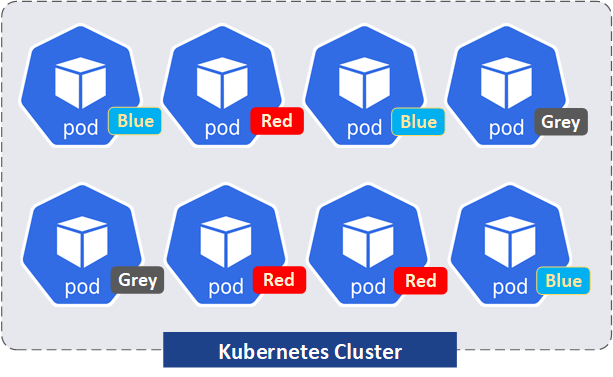
Die zweite Methode, um Objekte / Ressourcen im Kubernetes-Cluster zu organisieren und zu kennzeichnen, wird als „Labels“ bezeichnet. Kubernetes Objekte/Ressourcen werden mit Labels versehen, um sie später leichter finden und auswählen zu können. Fast alle erstellbaren Ressourcen (Pods, Services, Volumes, Nodes, ReplicaSets, Deployments, StatefulSets usw.) können mit Labels versehen werden.
Im Großen und Ganzen werden die Labels in drei Szenarien verwendet:
- Auswahl und Gruppierung. Man könnte bestimmte Ressourcen anhand ihrer Labels auswählen und gruppieren.
- Service Discovery. Man könnte z.B. einen Service so konfigurieren, dass er nur die Pods verwendet, die entsprechend gelabelt sind.
- ReplicaSets und Deployments. In diesem Use Case werden nur die Pods von ReplicaSets / Deployments verwendet, die ein bestimmtes Label tragen.
Aus technischer Sicht sind die Labels Schlüssel-Wert-Paare (Key-Value Pair (KVP)). Die Schlüssel-Wert-Paare sind mit einer bestimmten Ressource in einem Cluster verknüpft (gelabelt).
- Der Schlüssel (key): der Schlüssel ist eine eindeutige Bezeichnung des Labels.
- Der Wert, der durch den Schlüssel repräsentiert wird.
Beispiel eines Schlüssel-Wert-Paares:
- app=meineSuperApp
- "app" ist der Schlüssel
- "meineSuperApp" ist der Wert.
Die Schlüssel-Wert-Paare können nicht beliebig benannt werden und unterliegen bestimmten Regeln. In Kubernetes dürfen die Schlüssel für Labels maximal 63 Zeichen lang sein und die Werte dürfen bis zu 253 Zeichen lang sein und dürfen die nur Buchstaben, Ziffern, Bindestriche und Unterstriche enthalten. Weitere Einzelheiten sind hier zu finden.
Beispiel -Labels:
Im folgenden Beispiel wird ein Deployment mit dem Namen "mein-test-deployment" erstellt.
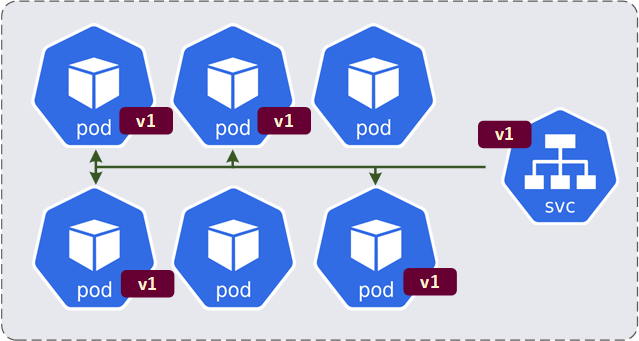
Der selector im Abschnitt spec definiert, welche Pods von dem Deployment verwaltet werden. Der matchLabels definiert, dass das Deployment alle Pods auswählt, die das Label "app=v1" (blau markiert) haben.
Die labels innerhalb der template Spezifikation definieren die Labels, die an diese Pods angehängt werden. Die Labels "app=v1" (grün markiert) werden auf jedem Pod gesetzt, der auf der Grundlage dieser YAML-Datei erstellt werden.
Die Werte im selector (matchLabels: app: v1) sollen mit den Werten in den labels übereinstimmen bzw. miteinander gematcht sein.
apiVersion: apps/v1kind: Deploymentmetadata: name: mein-test-deploymentspec: replicas: 3 selector: matchLabels: app: v1 template: metadata: labels: app: v1 spec: containers: - name: mein-supercontainer image: app-imageIn der Service-Datei dient der selector dazu, die Pods auszuwählen, an die der Service den Netzwerkverkehr weiterleitet soll. In diesem Fall sollte der „selector: app: v1“ mit den „labels: app: v1“ aus der Deployment-YAML gematcht werden.
apiVersion: v1kind: Servicemetadata: name: mein-servicespec: selector: app: v1 ports: - protocol: TCP port: 80 targetPort: 8080 type: ClusterIP
Was ist Kubernetes Annonations?
Annotations ist die dritte Methode, um Objekte in Kubernetes zu organisieren. Annotations werden in der Regel von Benutzern verwendet, um Entscheidungen darüber zu treffen, was mit einer bestimmten Ressource auf der Grundlage der Annotationen geschehen soll. In den Regeln sind diese Informationen für die Verwaltung von Objekten durch Kubernetes nicht relevant, aber für bestimmte Werkzeuge (z.B. Build-, Release- oder Image-Informationen) können sie nützlich sein.
Die Verwendung von Annotations kann die Integration externer Datenquellen überflüssig machen, da alle notwendigen Daten bereits an die Ressource angehängt sind und sich innerhalb des Clusters befinden. Jeder Ressourcentyp in Kubernetes kann mit einer Annotation versehen werden.
Aus technischen Sicht sind die Annotations ebenfalls Schlüssel-Wert-Paare, die in der Sektion Metadaten beschrieben werden. Die Schlüssel von Annotations können bis zu 63 Zeichen lang sein, ähnlich wie bei Labels. Eine Annotation kann aber bis zu 256 kB lang sein und somit wesentlich mehr Informationen enthalten.
Labels vs Annotations
Der Hauptunterschied zwischen Labels und Annotations liegt in ihrer Verwendung. Labels dienen der Identifizierung und Organisation von Kubernetes-Objekten und werden von Kubernetes selbst zur Verwaltung von Objekten verwendet. Annotations enthalten Informationen, die für die Verwaltung von Objekten durch Kubernetes nicht zwingend erforderlich sind, die aber für Entwickler, Operatoren und Tools nützlich sein können.
Beispiel - Annotations:
So können die Annotations in einer YAML-Datei aussehen:
apiVersion: apps/v1kind: Deploymentmetadata: name: mydeployment annotations: last-checked: "2023-05-23T18:25:43.511Z" git-commit: "d4f0f834c0743264f0435f62f13c5e1e2899fb2" owner: Anatoli repository: "https://github.com/kubernetes/"spec: replicas: 3 selector: matchLabels: app: mein-super-app template: metadata: labels: app: mein-super-app spec: containers: - name: mein-container image: mein-imageoder hier:
apiVersion: kyverno.io/v1
kind: ClusterPolicy
metadata:
name: always-pull-images
annotations:
policies.kyverno.io/title: Always Pull Images
policies.kyverno.io/category: Sample
policies.kyverno.io/severity: medium
policies.kyverno.io/subject: Pod
policies.kyverno.io/description: >-
By default, images that have already been pulled can be accessed by other Pods without re-pulling them if the name and tag are known.
Teil 4: Workload Objekte